ㅁ 개요
O 프로그램 소개
- 이번 내용은 openvoice v2를 활용하여 다양한 음성 활용 방법을 알아보고, 최종적으로 일론머스크의 한국어 목소리로 파기차차를 칭찬하는 내용을 만드는 방법에 대하여 자세히 알아 보겠습니다.
주의 !!
이번 글은 반드시 옳바른 학습 용도로만 사용하시기 바랍니다. 그 외 허가되지 않은 방법이나 불법적인 목적(예: 피싱 등)으로 사용시 발생하는 모든 책임은 본인에게 있음을 알립니다.
O 사전 준비 사항
권장 사양이 어느 정도 되는지는 잘 모르겠습니다. 다만, 제가 사용한 스펙을 아래와 같이 공개하오니 참고 하시기 바랍니다.(사양이 좋지 않아도 돌아는 갈 것으로 보입니다. 단, 느림 주의!!)
-리눅스 우분투 22.04
-CPU 4장
-메모리 8G
-GPU가 있으면 좋으나 없어도 관계없음
O 진행 순서
진행 순서는 크게 아래와 같습니다.
I.환경설정
-여기서는 아나콘다 설치, conda를 사용하기 위한 환경변수 설정, 그리고 가상환경을 생성하고 진입하는 방법에 대해 설명합니다.
II.openvoice v2 활용하기
-OpenVoice와 checkpoints_v2를 다운로드하여 예제 음성(일론머스크의 음성)을 학습시킨 후 예제 음성을 11가지 버전(영어, 스페인어, 프랑스어 중국어, 일본어, 한국어 등)으로 만드는 방법에 대해 설명 합니다.
I. 환경 설정
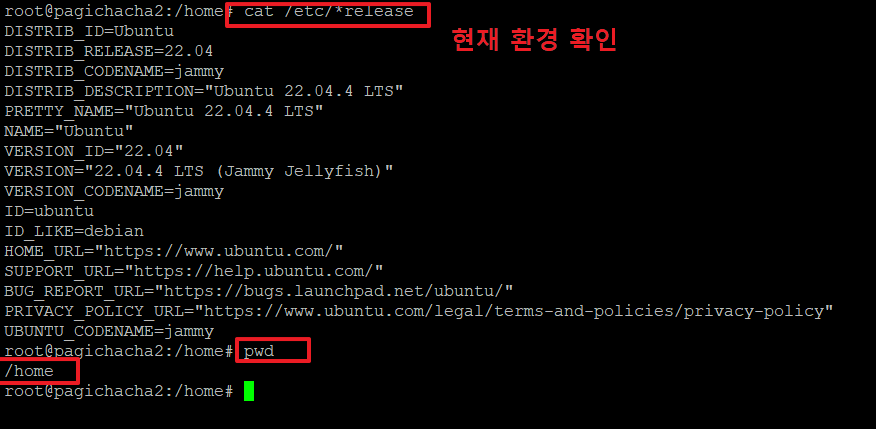
1. 리눅스 설치 후 기본 환경을 아래 명령으로 확인합니다.
>cat /etc/*release
>pwd
/home <-- 저는 여기에서 작업을 하였습니다.
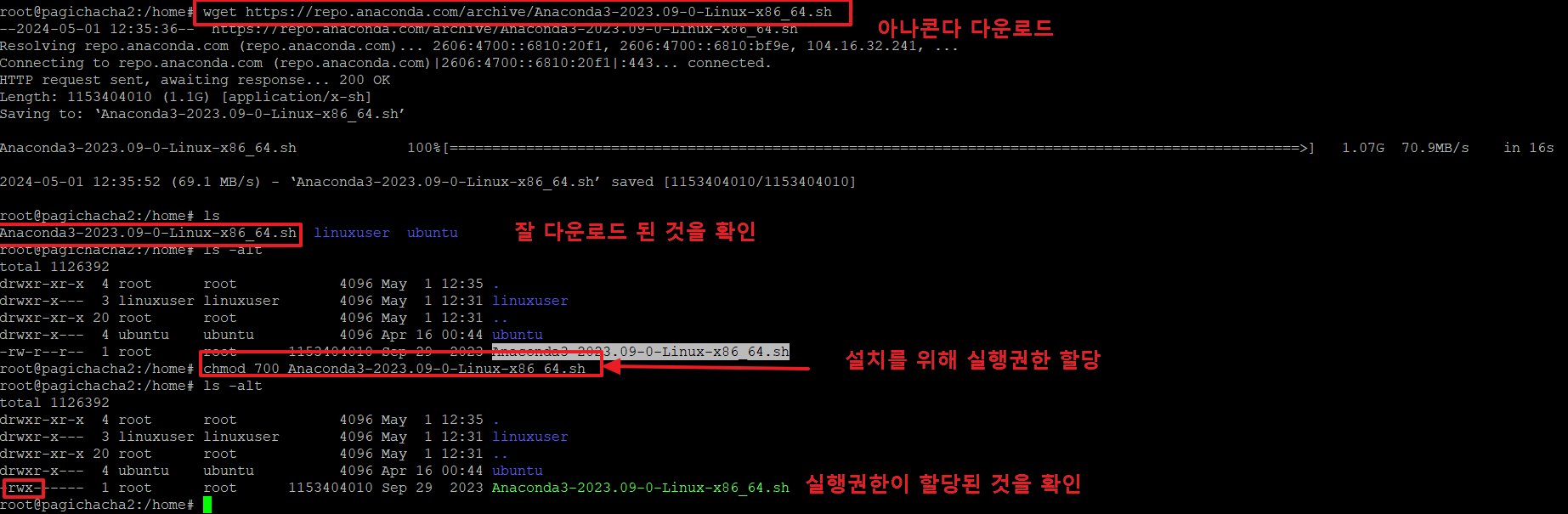
2.금번 글의 내용을 수행하기 위해서는 아나콘다를 설치해야 합니다.
아래 명령으로 아나콘다를 다운로드 합니다.
ls : 다운로드가 잘 되었는지 확인 후
chmod 700 Anaconda3-2023.09-0-Linux-x86_64.sh : 파일에 실행권한을 주어 실행할 수 있는 상태로 만듭니다.
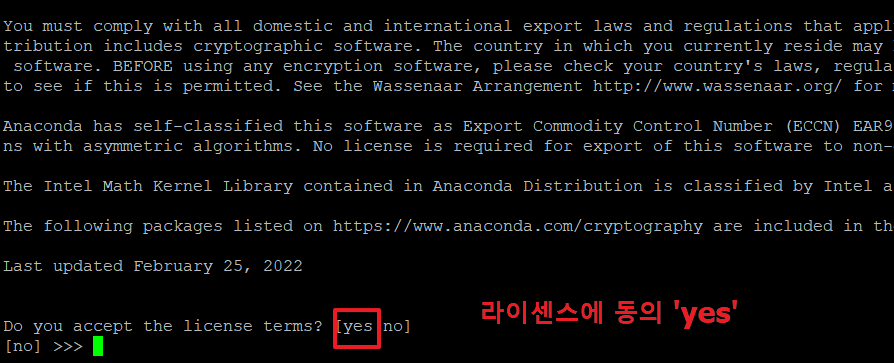
3. 아래 명령으로 아나콘다를 설치 합니다.
계속하기 위해 '엔터'를 누릅니다.

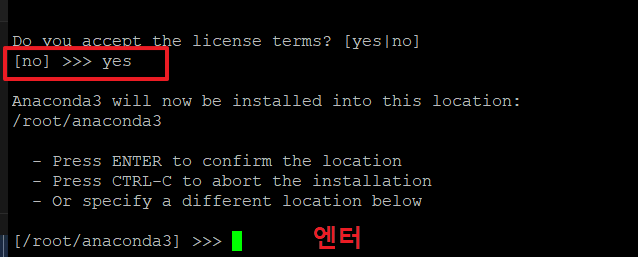
4.아래 화면에서 'yes'를 입력 후 엔터를 누릅니다.
5. 설치 위치는 크게 상관 없으므로 기본 위치(/root/anaconda3)에 설치 하기 위해 '엔터'를 누릅니다.
6. 아래와 같이 'installation finished' 가 나오면 잘 설치된 것입니다.
마지막 부분에 그냥 '엔터'를 눌러 이전 상태로 되돌리지 않습니다.
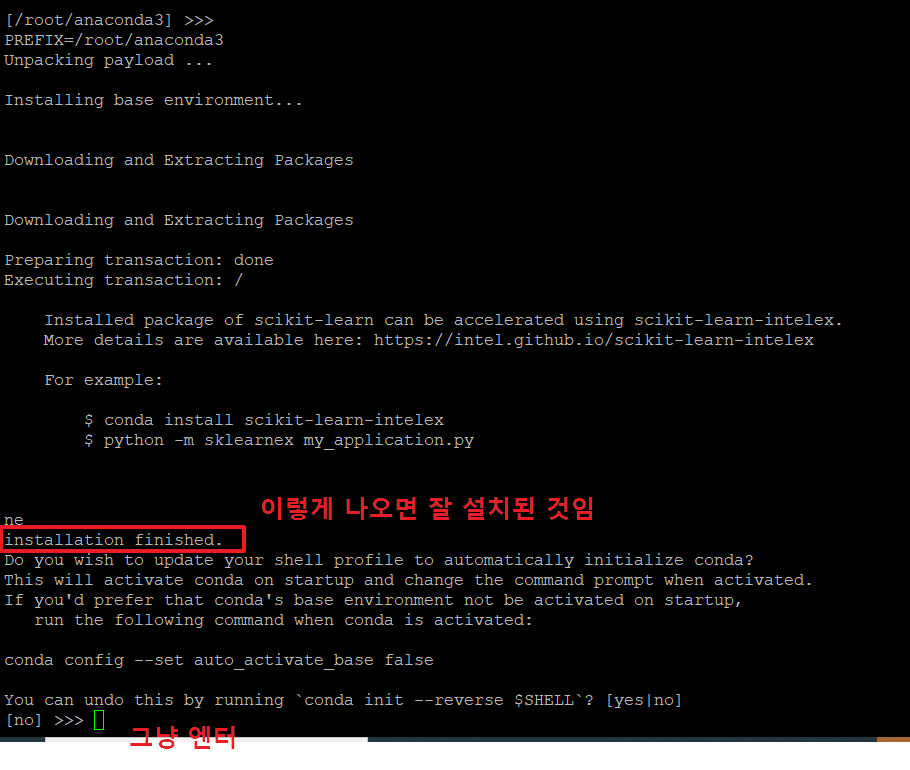
7. 아래와 같이 나오면 아나콘다 설치가 완료된 것입니다.
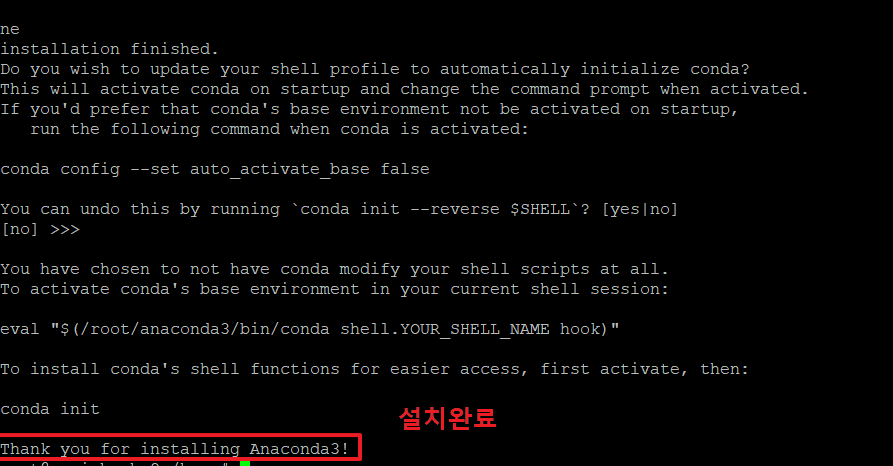
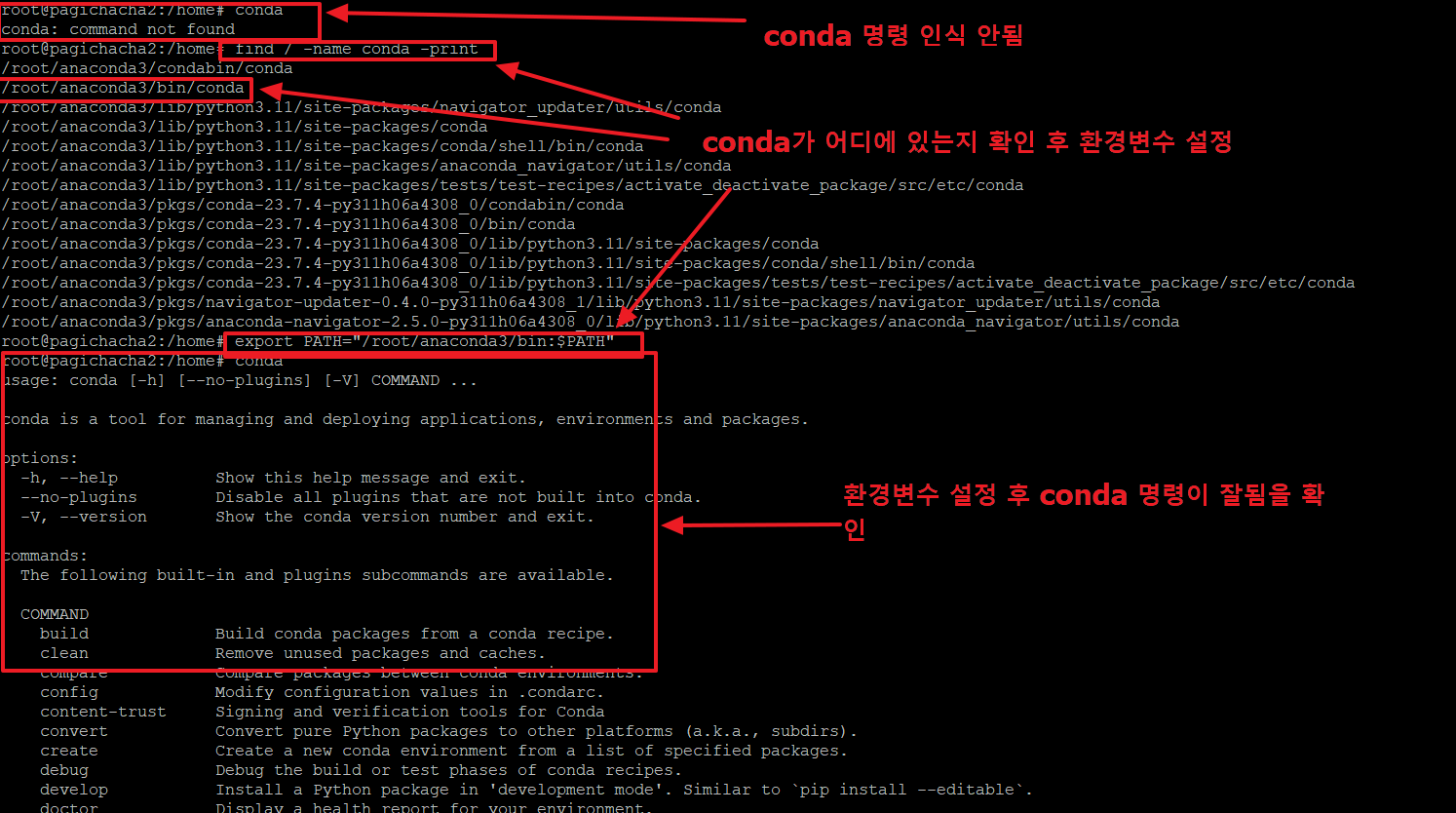
8. conda명령을 사용하였으나, 명령을 인식하지 못하고 있습니다.
먼저 conda 파일을 아래와 같이 찾습니다.
>find / -name conda -print
/root/anaconda3/bin/conda <-- 여기에 콘다가 위치한걸 알아냈습니다.
conda 명령이 실행되도록 path를 설정해 주어야 합니다. 아래와 같이 입력합니다.
이제 conda를 입력하면 아래 정상적으로 관련 내용이 나오는 것을 확인할 수 있습니다.
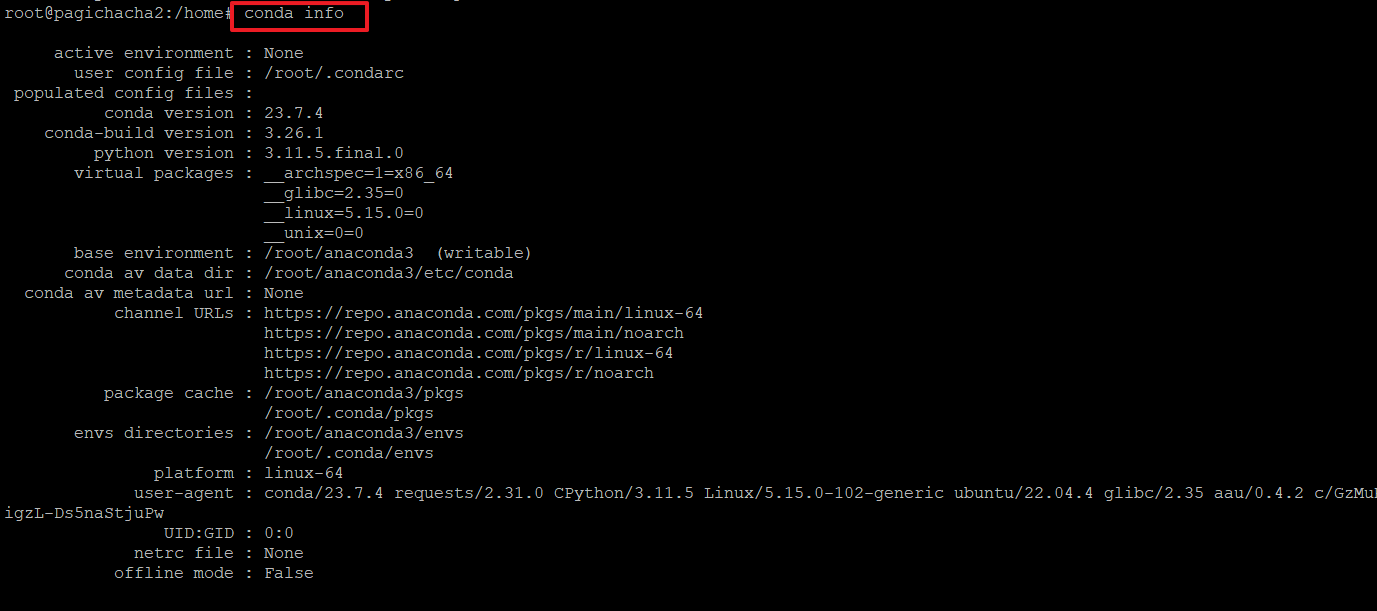
9.아래 명령으로 콘다의 정보를 확인합니다.
>conda info
10. 아래와 같은 명령으로 openvoice라는 이름의 가상환경을 생성합니다.
(가상환경 내에서 사용할 파이썬 버전은 3.9를 사용할 것입니다.)
11. 새로운 패키지를 설치할 것을 묻는데, 'y'입력 합니다.
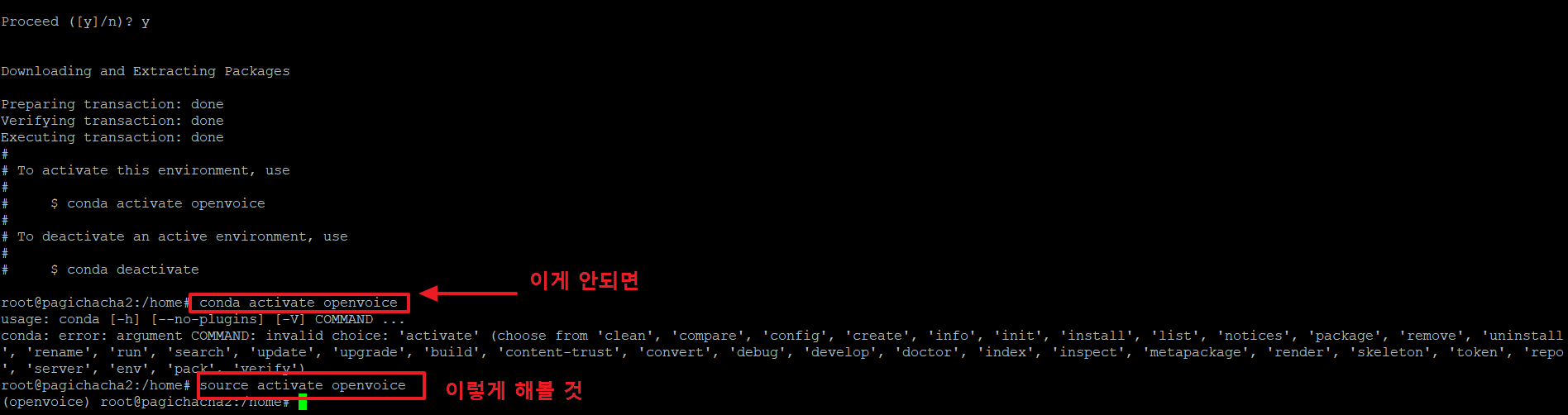
12. 가상환경으로 진입하려면 아래와 같은 명령을 사용하여 진입합니다.
>conda activate openvoice
위의 명령이 안되는 경우 아래 명령을 사용합니다.
>source activate openvoice
II. openvoice v2 활용하기
13. 다양한 음성을 활용하기 위해 우리는 openvoice를 사용할 예정이며, 아래 git에서 openvoice에서 제공하는 파일을 다운로드 받습니다.
>git clone https://github.com/myshell-ai/OpenVoice.git
위 명령 실행 후 무엇이 받아졌는지 ls명령으로 확인합니다.
>ls
아래 그림처럼 'OpenVoice' 디렉토리가 생성된 것을 알 수 있습니다.
>cd OpenVoice 명령으로 해당 디렉토리로 이동 후 어떤 파일들이 생성되었는지 살펴 봅니다.

14. 아래 명령으로 현재 디렉토리의 소스코드를 기반으로 파이썬 패키지를 개발 모드로 설치합니다.
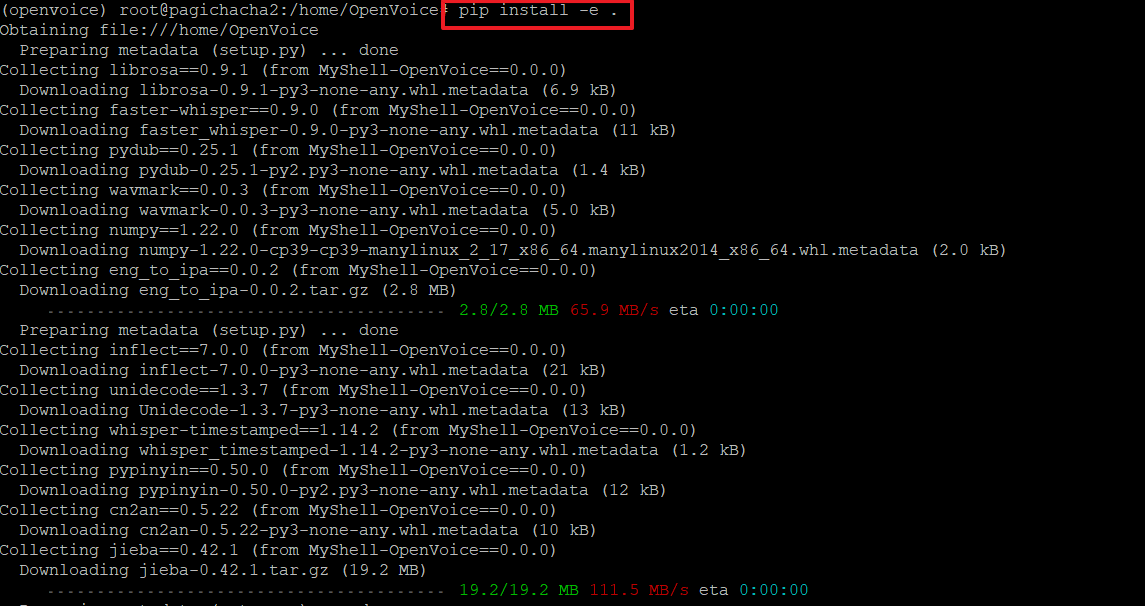
15. 아래와 같이 'successfully~~' 가 보이면 잘 설치된 것입니다.
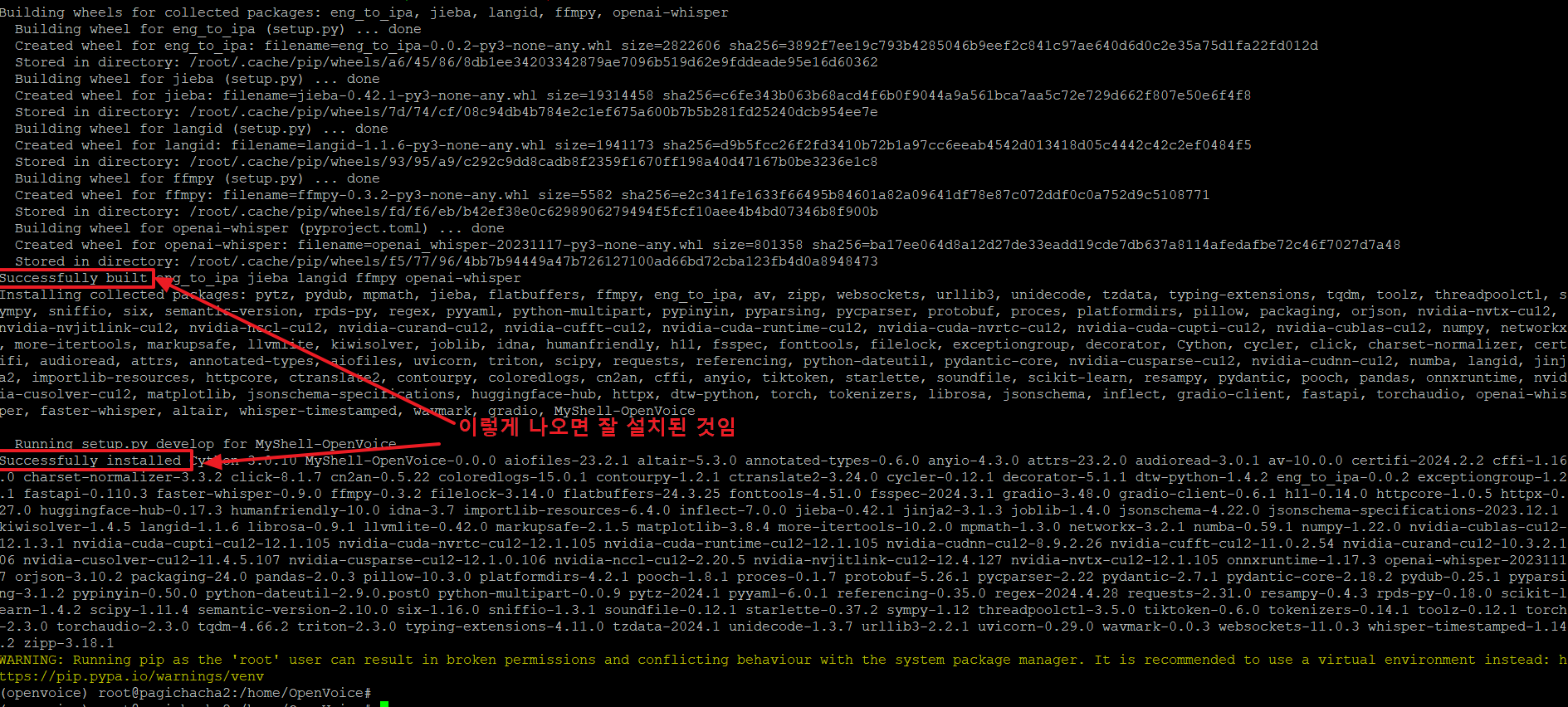
16. openvoice를 사용하기 위해 아래와 같은 명령으로 checkpoints_v2 파일을 다운로드 받습니다.
>wget https://myshell-public-repo-hosting.s3.amazonaws.com/openvoice/checkpoints_v2_0417.zip

17. 다운로드 받은 zip파일의 압축을 아래 명령으로 해제합니다.
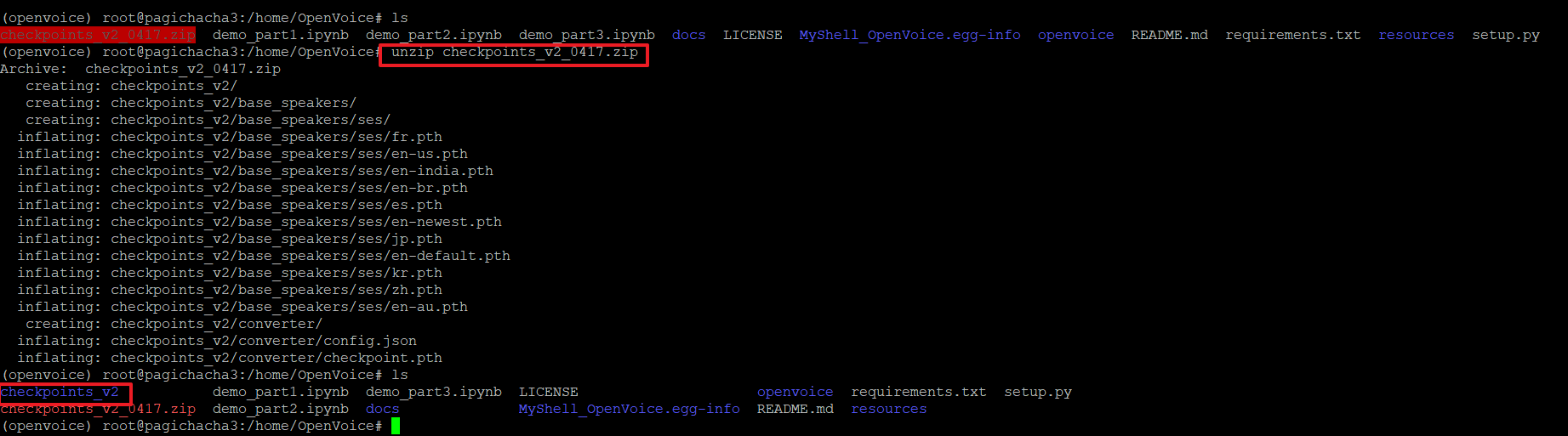
18. 고품질의 다국어 TTS인 MeloTTS를 기본 스피커로 사용하기위해 설치합니다. MeloTTS는 기본적으로 영어(미국어, 영국어, 인도어, 호주어, 기본값), 스페인어, 프랑스어, 중국어, 일본어, 한국어 등의 언어를 지원합니다.
>pip install git+https://github.com/myshell-ai/MeloTTS.git
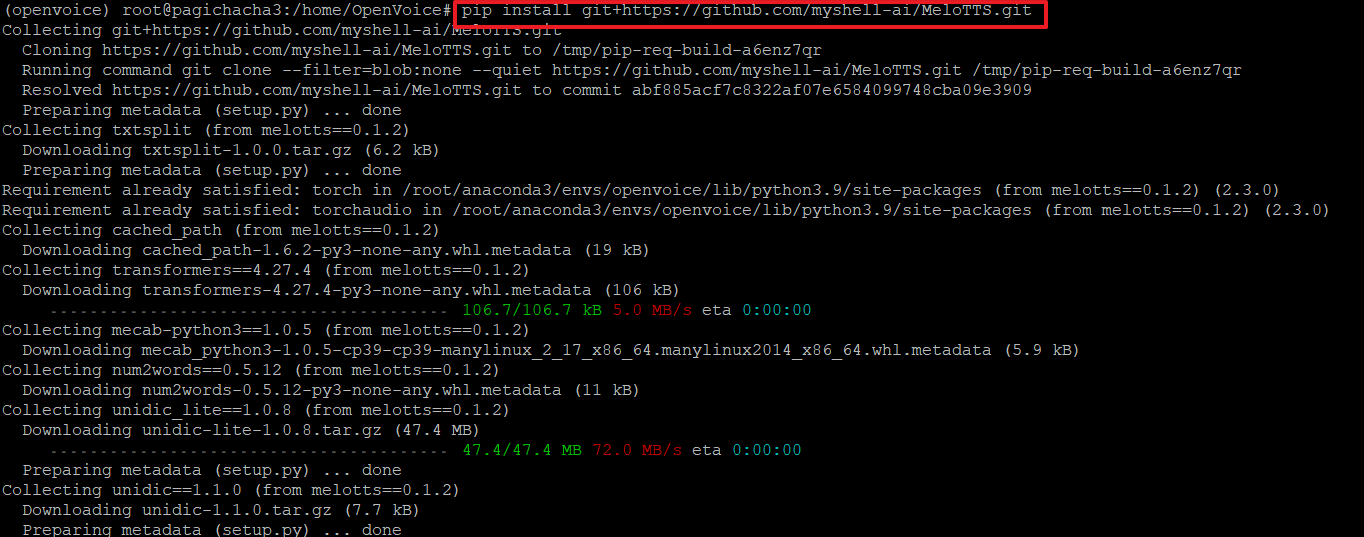
19. 일본어 텍스트를 분석하기 위해 unidic 사전을 다운로드 합니다.
>python -m unidic download

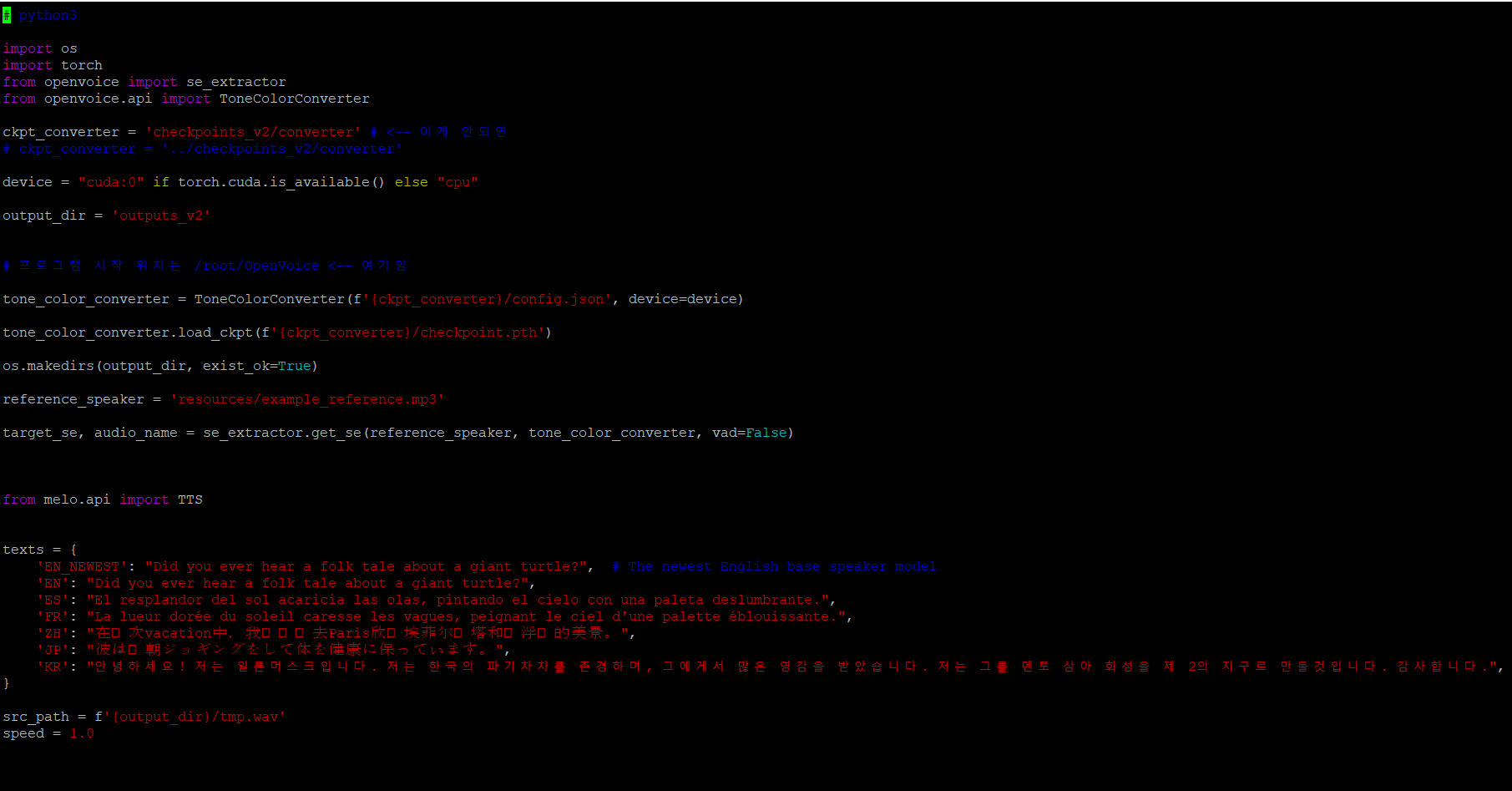
20. 파이썬 소스코드를 만들어서 한번에 실행할 예정이므로 아래와 같이 코딩 후 복사한 다음 원격 리눅스의 터미널에서 vi 편집기를 열어서 붙여 넣습니다.
# python3
import os
import torch
from openvoice import se_extractor
from openvoice.api import ToneColorConverter
ckpt_converter = 'checkpoints_v2/converter' # <-- 이게 안되면
# ckpt_converter = '../checkpoints_v2/converter'
device = "cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = 'outputs_v2'
# 프로그램 시작 위치는 /root/OpenVoice <-- 여기임
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
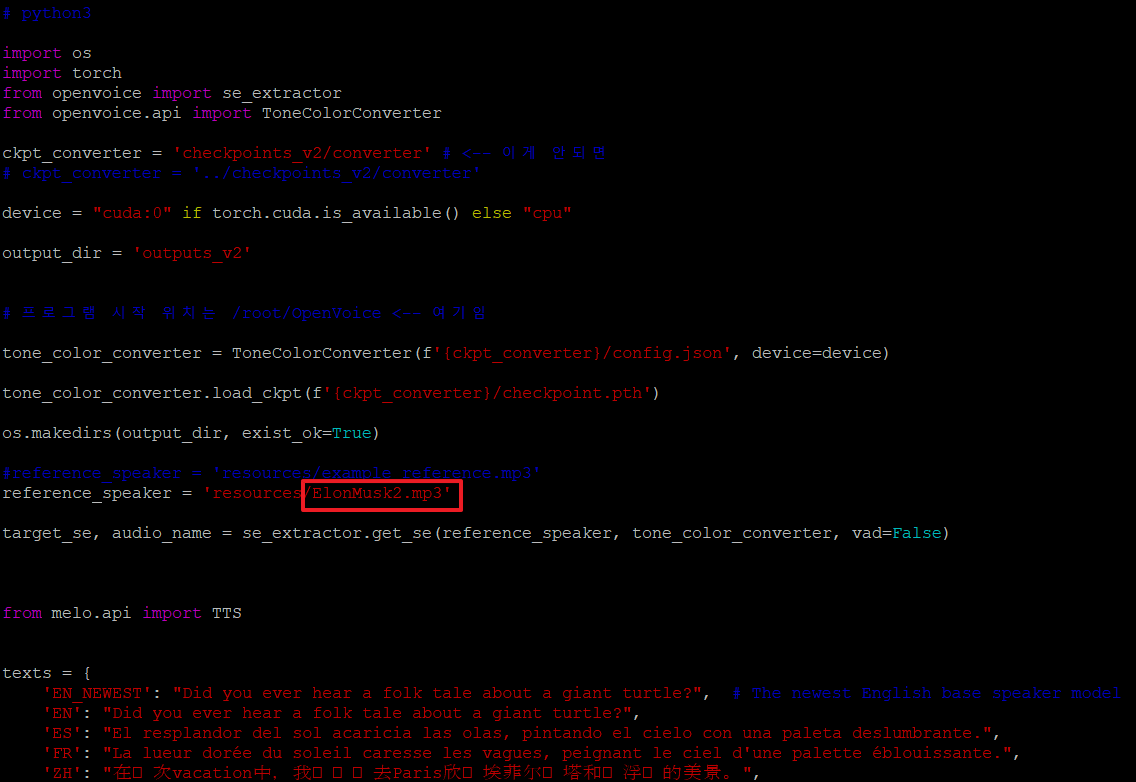
reference_speaker = 'resources/example_reference.mp3'
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, vad=False)
from melo.api import TTS
texts = {
'EN_NEWEST': "Did you ever hear a folk tale about a giant turtle?", # The newest English base speaker model
'EN': "Did you ever hear a folk tale about a giant turtle?",
'ES': "El resplandor del sol acaricia las olas, pintando el cielo con una paleta deslumbrante.",
'FR': "La lueur dorée du soleil caresse les vagues, peignant le ciel d'une palette éblouissante.",
'ZH': "在这次vacation中,我们计划去Paris欣赏埃菲尔铁塔和卢浮宫的美景。",
'JP': "彼は毎朝ジョギングをして体を健康に保っています。",
'KR': "안녕하세요! 저는 일론머스크입니다. 저는 한국의 파기차차를 존경하며, 그에게서 많은 영감을 받았습니다. 저는 그를 멘토 삼아 화성을 제 2의 지구로 만들것입니다. 감사합니다.",
}
src_path = f'{output_dir}/tmp.wav'
speed = 1.0
for language, text in texts.items():
model = TTS(language=language, device=device)
speaker_ids = model.hps.data.spk2id
for speaker_key in speaker_ids.keys():
speaker_id = speaker_ids[speaker_key]
speaker_key = speaker_key.lower().replace('_', '-')
# source_se = torch.load(f'../checkpoints_v2/base_speakers/ses/{speaker_key}.pth', map_location=device)
source_se = torch.load(f'checkpoints_v2/base_speakers/ses/{speaker_key}.pth', map_location=device)
model.tts_to_file(text, speaker_id, src_path, speed=speed)
save_path = f'{output_dir}/output_v2_{speaker_key}.wav'
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
>vi openvoice_part3.py
<-- 편집상태에서 'i'를 입력하여 입력모드에서 붙여넣기를 하시면 됩니다.
openvoice_part3.py 파일이 생성되었으면 아래와 같이 실행권한을 추가합니다.
>chmod 700 openvoice_part3.py
그리고 아래 명령으로 파이썬을 실행합니다.
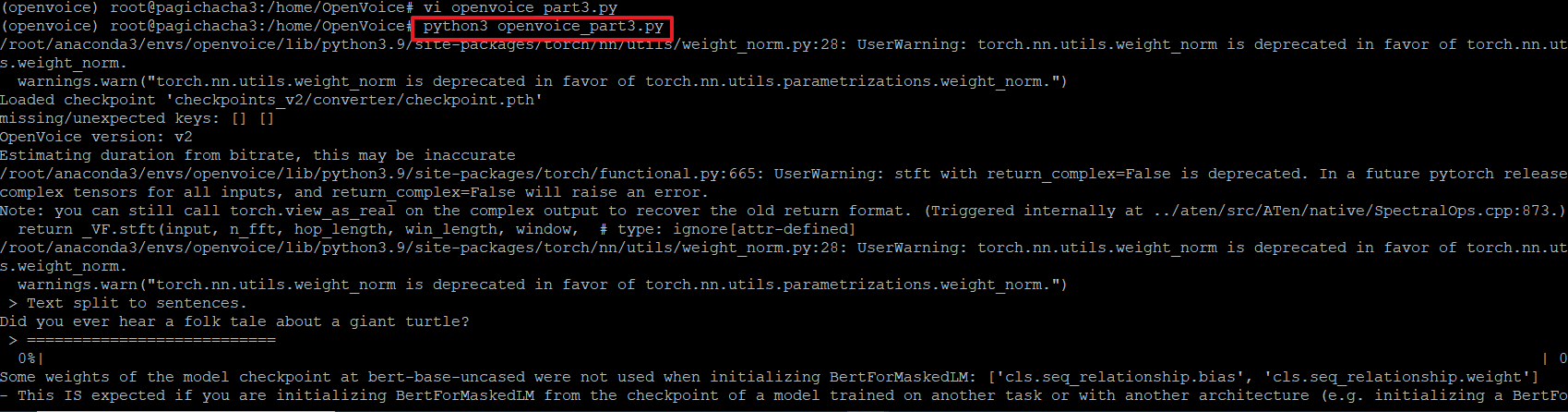
>python3 openvoice_part3.py

20. 그런데 아래와 같이 'CUDA'관련 에러가 발생하고 있습니다. 이는 GPU가 설치되어 있지 않아 발생하는 오류로 관련 소스코드의 내용을 변경해줘야 합니다.
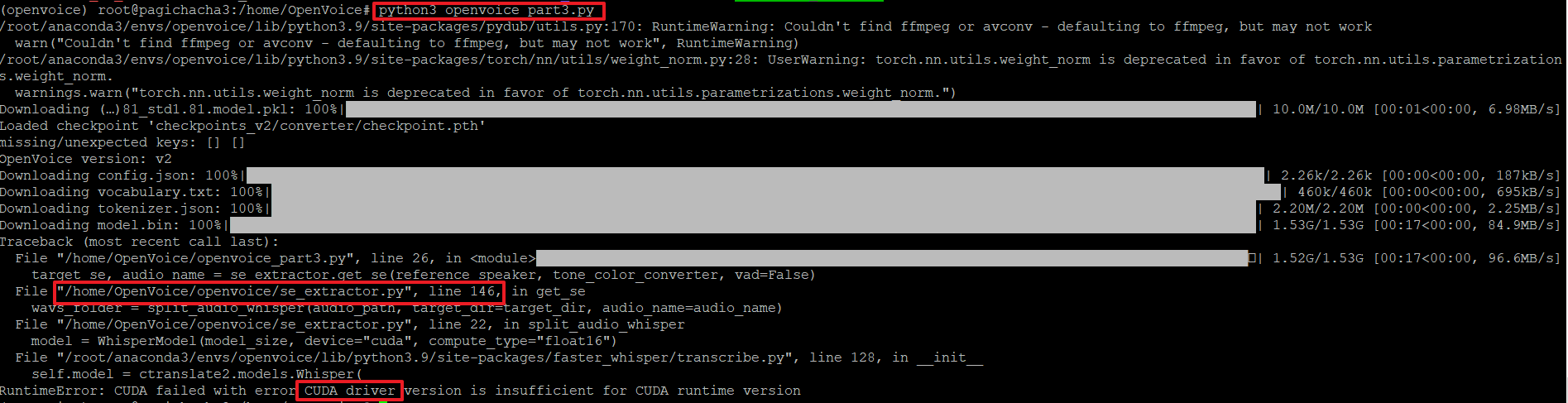
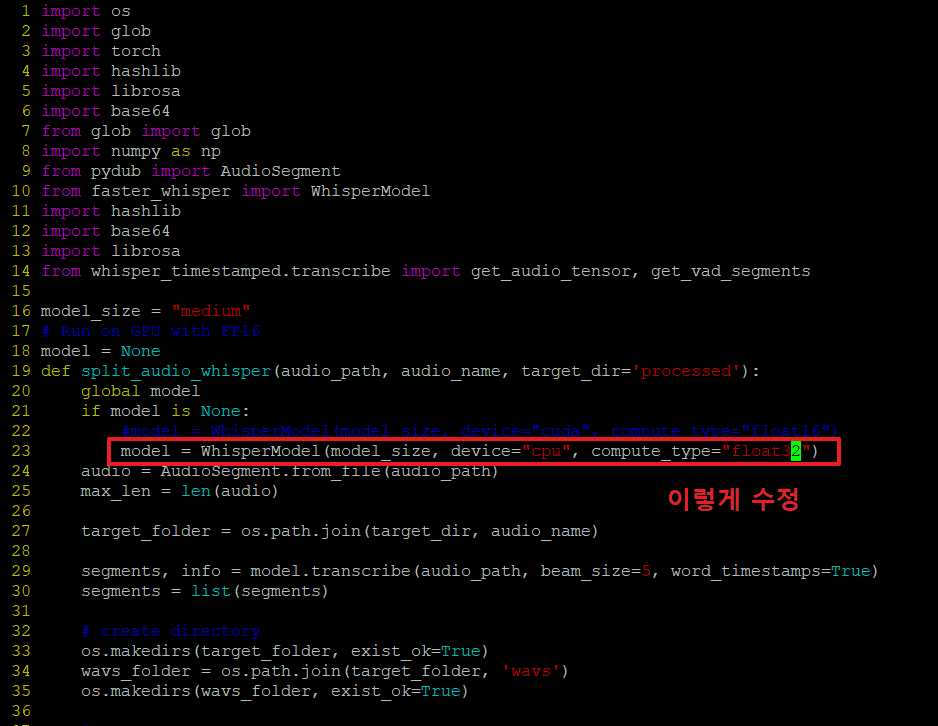
21. 아래 경로로 이동하여 'vi se_extractor.py' 파일의 내용을 아래와 같이 수정합니다.
model = WhisperModel(model_size, device="cuda", compute_type="float16")<-- 이거를
model = WhisperModel(model_size, device="cpu", compute_type="float32") <---이렇게 수정

22. 다시 파이썬 파일을 실행해 봅니다.

23. 아래와 같이 다시 'ffprobe' 관련 에러가 발생하는데, ffmpeg를 설치하지 않아 발생하는 오류입니다.
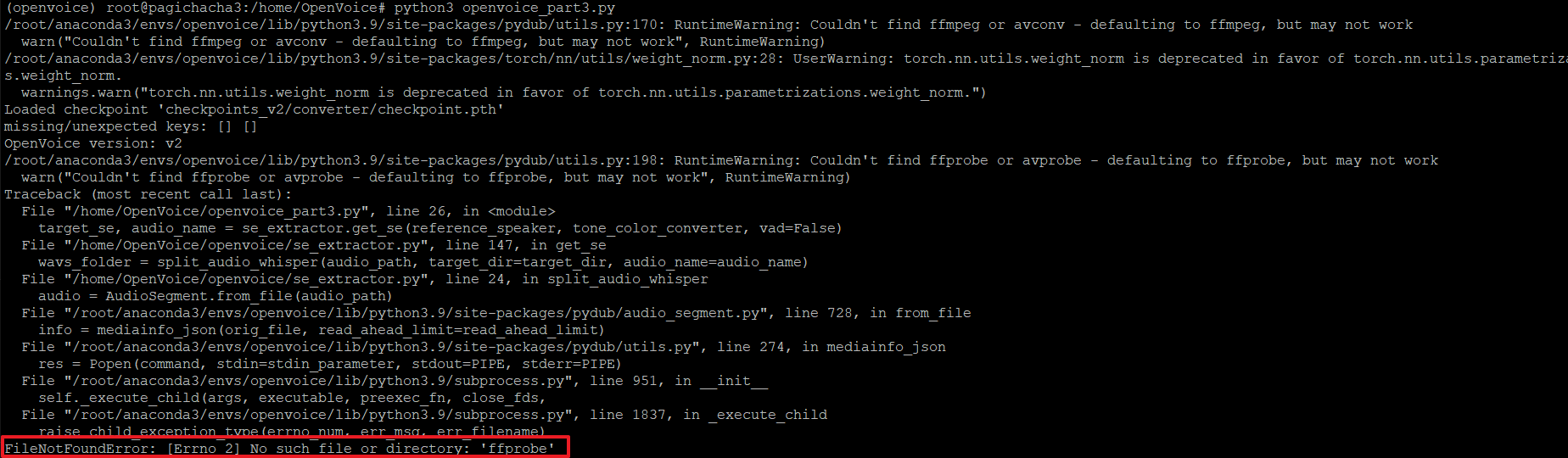
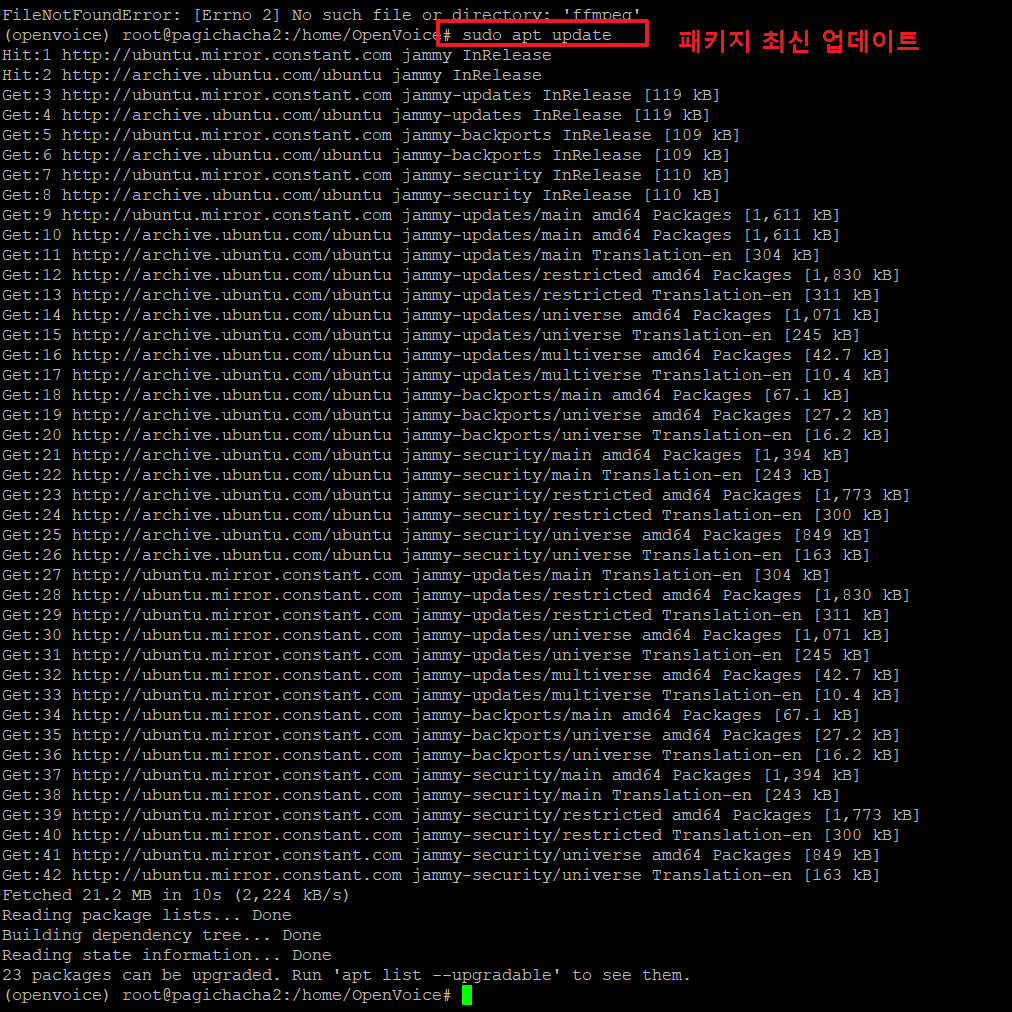
24. ffmpeg를 설치하기 위해서 아래와 같이 진행합니다.
>sudo apt update <-- 패키지를 최신으로 업데이트 합니다.
25. 아래 명령으로 ffmpeg를 설치 합니다.
>sudo apt install ffmpeg
아래 '계속하시겠습니까?' 가 나오면 'Y'를 입력합니다.
26. 다시 파이썬 파일을 실행합니다. 에러가 발생하지 않고 잘 실행되었습니다.
>python3 openvoice_part3.py
27. 결과 음성파일들은 outputs_v2 디렉토리에 저장됩니다.
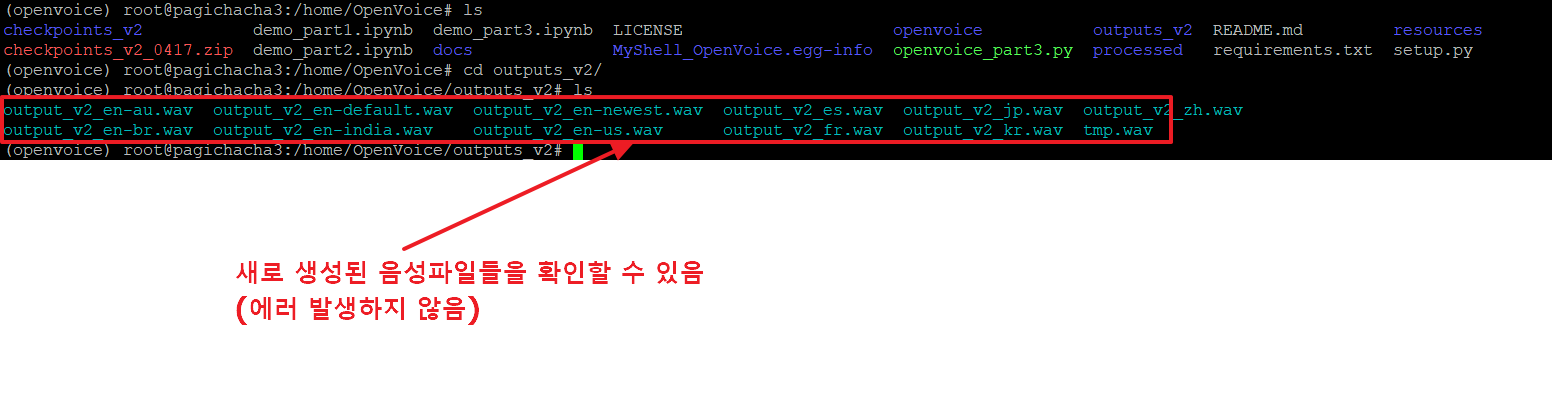
여기서의 음성은 기본 예제 파일을 일론머스코로 바꾸어 주지 않았기 때문에 기본 스피커의 음성을 학습하여 한국어로 이야기한 결과가 저장되었습니다.
기본 스피커의 음성
기본 스피커의 음성을 학습 후 한국어 음성으로 변조한 음성
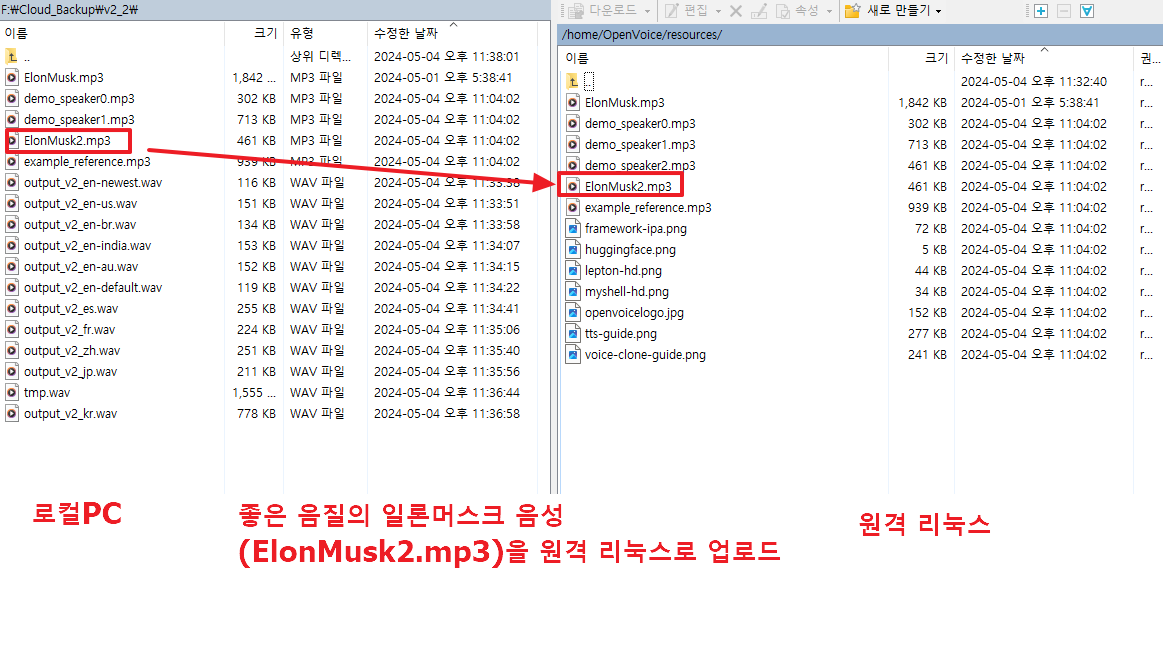
28. 양질의 일론머스크 음성을 로컬PC -> 원격 리눅스로 업로드 합니다.
(양질의 일론머스크 음성은 resources 디렉토리에 demo_speaker2.mp3 파일로 기본 포함되어 있습니다.)
29.일론머스크의 음성을 기본 스피커로 사용해야 하므로 소스를 아래와 같이 변경 후 다시 실행합니다.

30. 결과 파일을 로컬PC로 복사 후 음성을 들어보면 결과가 잘 만들어진 것을 확인할 수 있습니다.
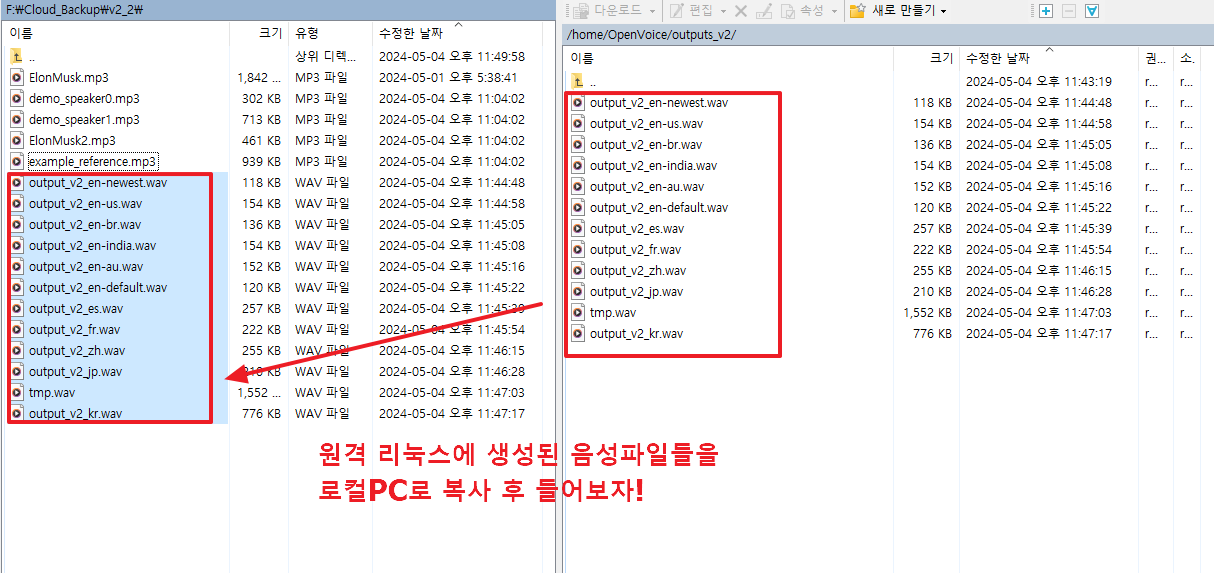
output_v2_en-au.wav : 일론머스크의 호주영어 버전
output_v2_en-br.wav : 일론머스크의 영국영어 버전
output_v2_en-default.wav : 일론머스크의 기본영어 버전
output_v2_en-india.wav : 일론머스크의 인도영어 버전
output_v2_en-us.wav : 일론머스크의 미국영어 버전
output_v2_es.wav : 일론머스크의 스페인어 버전
output_v2_fr.wav : 일론머스크의 프랑스어 버전
output_v2_jp.wav : 일론머스크의 일본어 버전
output_v2_kr.wav : 일론머스크의 한국어 버전
output_v2_zh.wav : 일론머스크의 중국어 버전
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
감사합니다.
'파이썬 AI 실습 > (음성변조)일론머스크의 멘토가 되다!' 카테고리의 다른 글
| 음성변조 openvoice v1- 일론머스크의 멘토가 되다.!! (2) | 2024.05.02 |
|---|