ㅁ 개요
O 프로그램 소개
- 이번 내용은 openvoice v1를 활용하여 다양한 음성 활용 방법을 알아보고, 최종적으로 일론머스크의 목소리로 파기차차를 칭찬하는 내용을 만드는 방법에 대하여 자세히 알아 보겠습니다.
주의 !!
이번 글은 반드시 옳바른 학습 용도로만 사용하시기 바랍니다. 그 외 허가되지 않은 방법이나 불법적인 목적(예: 피싱 등)으로 사용시 발생하는 모든 책임은 본인에게 있음을 알립니다.
O 사전 준비 사항
권장 사양이 어느 정도 되는지는 잘 모르겠습니다. 다만, 제가 사용한 스펙을 아래와 같이 공개하오니 참고 하시기 바랍니다.(사양이 좋지 않아도 돌아는 갈 것으로 보입니다. 단, 느림 주의!!)
-리눅스 우분투 22.04
-CPU 4장
-메모리 8G
-GPU가 있으면 좋으나 없어도 관계없음
O 진행 순서
진행 순서는 크게 아래와 같습니다.
I.환경설정
-여기서는 아나콘다 설치, conda를 사용하기 위한 환경변수 설정, 그리고 가상환경을 생성하고 진입하는 방법에 대해 설명합니다.
II.openvoice 활용하기
-OpenVoice와 checkpoints를 다운로드하여 예제 음성을 학습시킨 후 예제 음성을 3가지 버전(기본음성, 속삭임 음성, 중국어 음성)으로 만드는 방법에 대해 설명 합니다.
I. 환경 설정
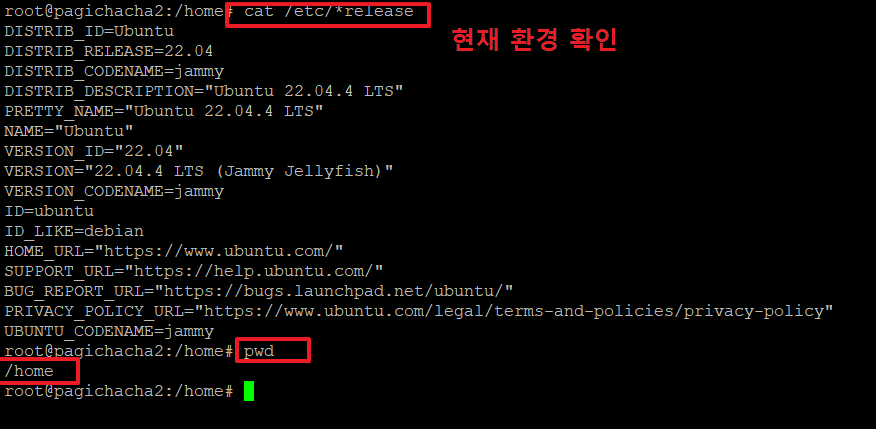
1. 리눅스 설치 후 기본 환경을 아래 명령으로 확인합니다.
>cat /etc/*release
>pwd
/home <-- 저는 여기에서 작업을 하였습니다.
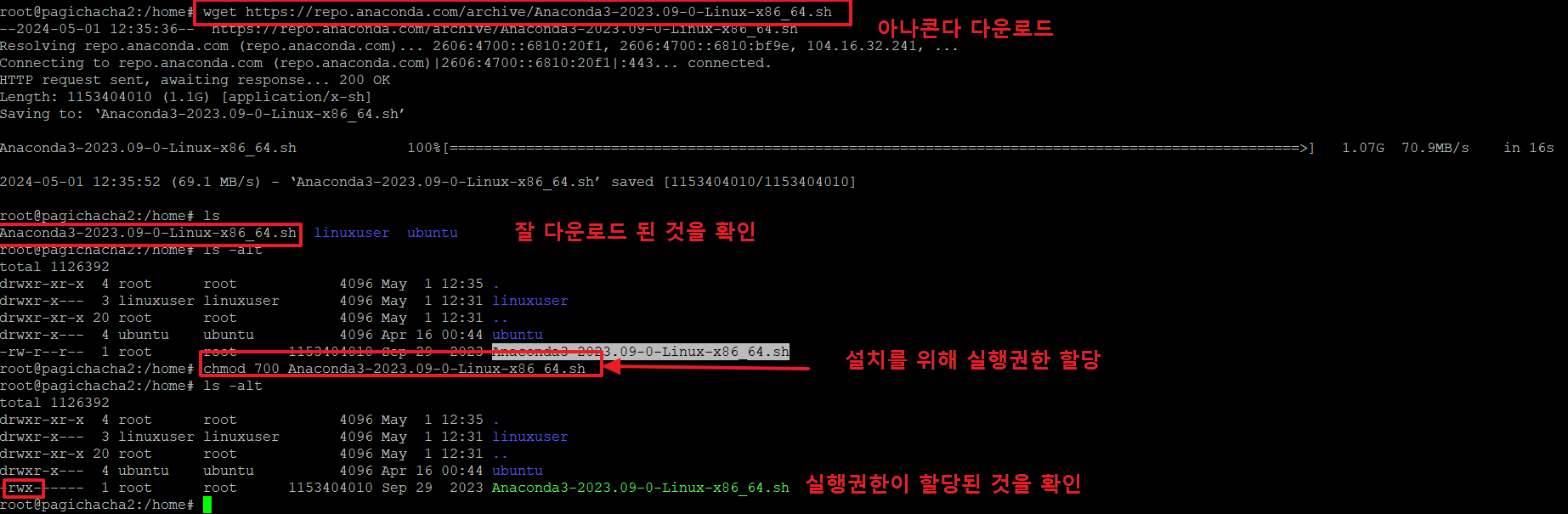
2.금번 글의 내용을 수행하기 위해서는 아나콘다를 설치해야 합니다.
아래 명령으로 아나콘다를 다운로드 합니다.
ls : 다운로드가 잘 되었는지 확인 후
chmod 700 Anaconda3-2023.09-0-Linux-x86_64.sh : 파일에 실행권한을 주어 실행할 수 있는 상태로 만듭니다.
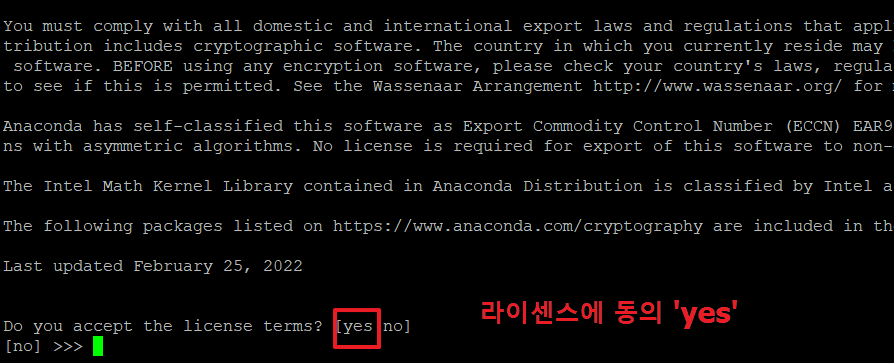
3. 아래 명령으로 아나콘다를 설치 합니다.
계속하기 위해 '엔터'를 누릅니다.

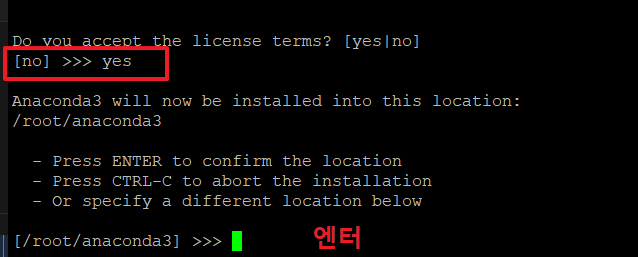
4.아래 화면에서 'yes'를 입력 후 엔터를 누릅니다.
5. 설치 위치는 크게 상관 없으므로 기본 위치(/root/anaconda3)에 설치 하기 위해 '엔터'를 누릅니다.
6. 아래와 같이 'installation finished' 가 나오면 잘 설치된 것입니다.
마지막 부분에 그냥 '엔터'를 눌러 이전 상태로 되돌리지 않습니다.
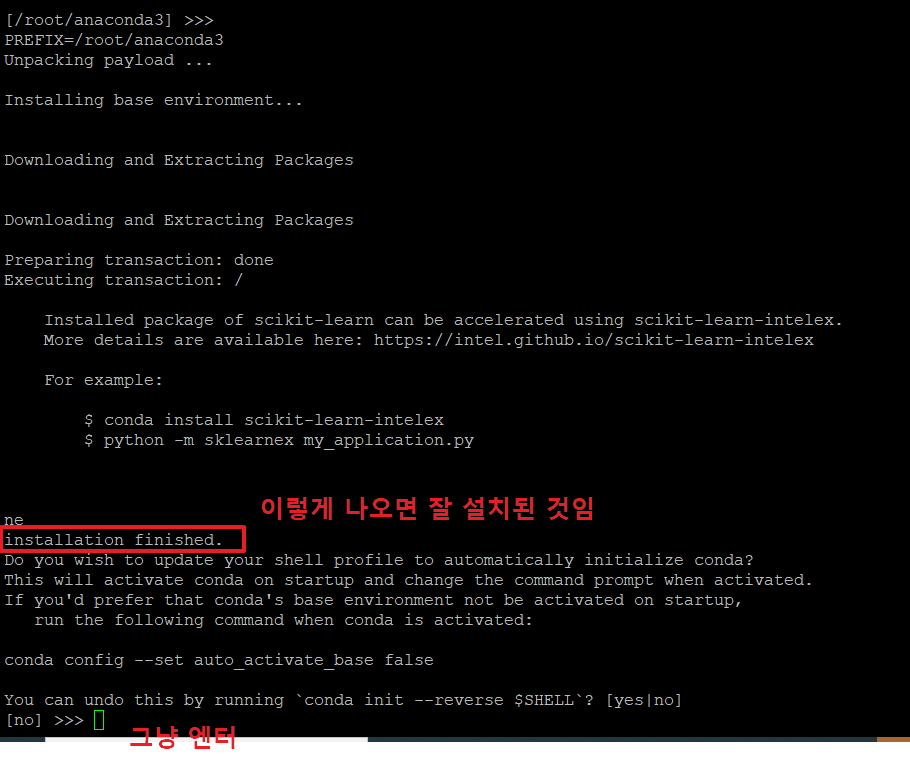
7. 아래와 같이 나오면 아나콘다 설치가 완료된 것입니다.
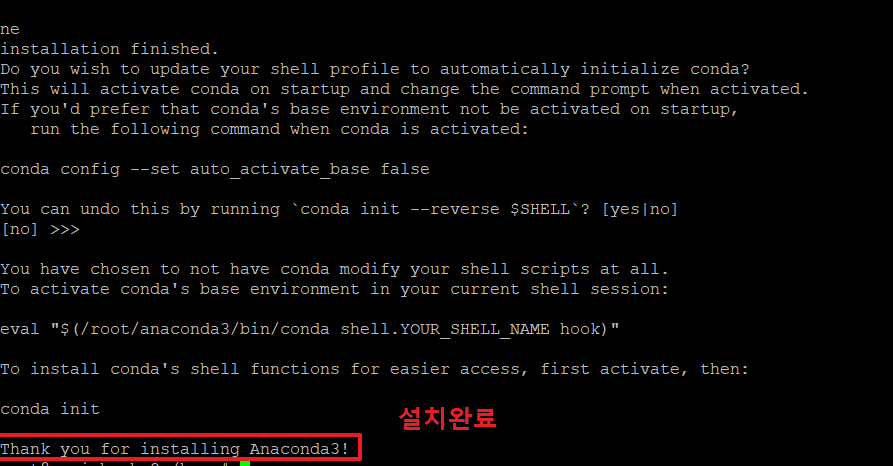
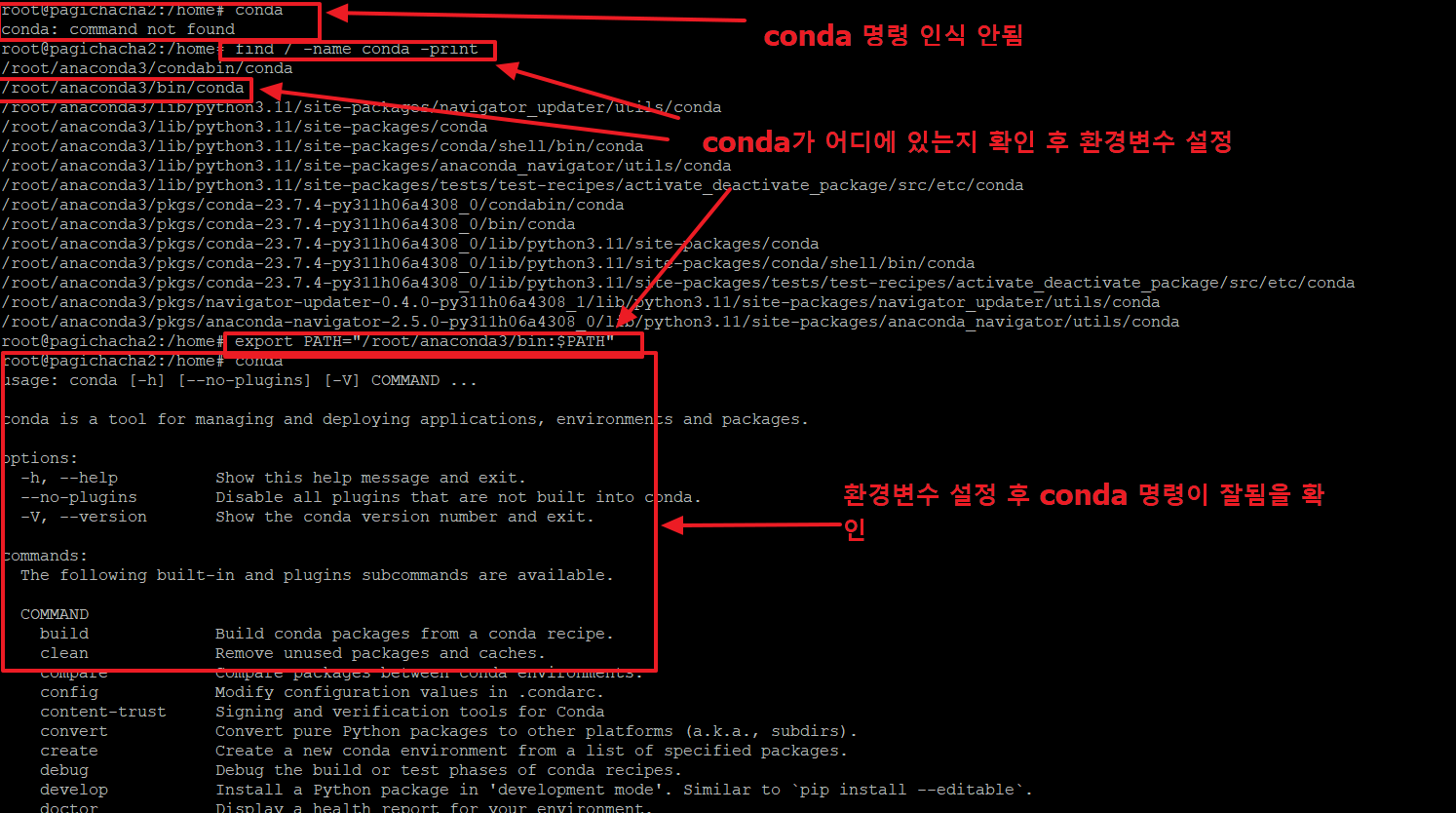
8. conda명령을 사용하였으나, 명령을 인식하지 못하고 있습니다.
먼저 conda 파일을 아래와 같이 찾습니다.
>find / -name conda -print
/root/anaconda3/bin/conda <-- 여기에 콘다가 위치한걸 알아냈습니다.
conda 명령이 실행되도록 path를 설정해 주어야 합니다. 아래와 같이 입력합니다.
이제 conda를 입력하면 아래 정상적으로 관련 내용이 나오는 것을 확인할 수 있습니다.
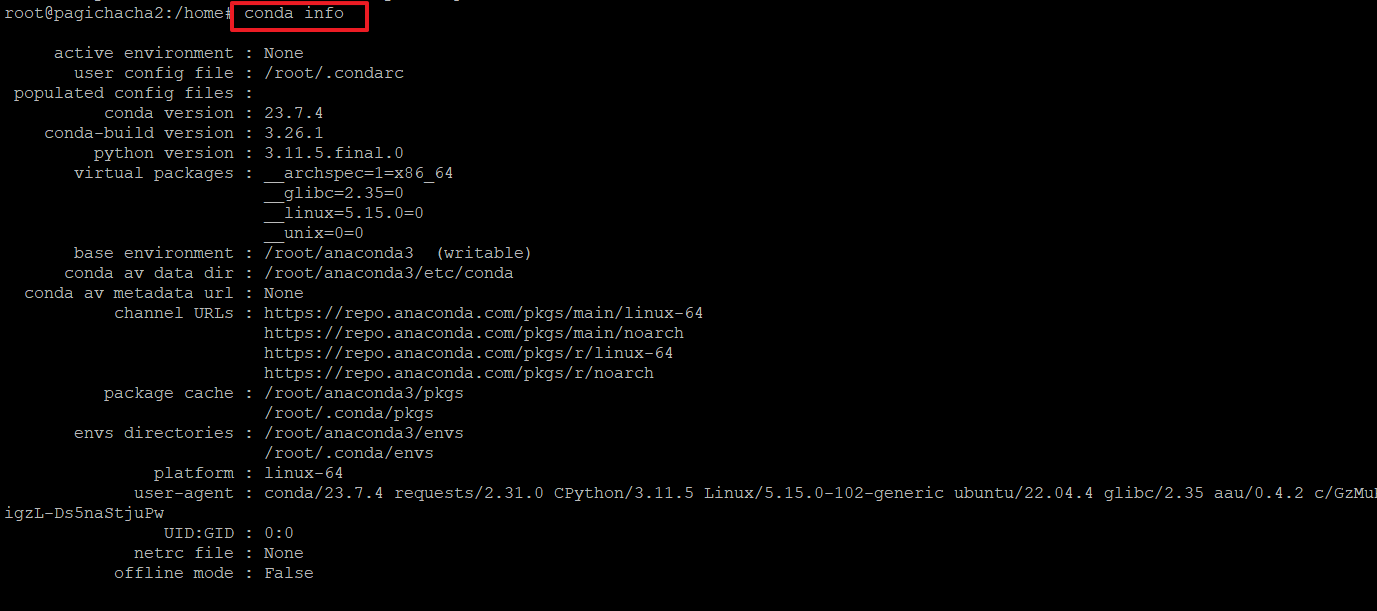
9.아래 명령으로 콘다의 정보를 확인합니다.
>conda info
10. 아래와 같은 명령으로 openvoice라는 이름의 가상환경을 생성합니다.
(가상환경 내에서 사용할 파이썬 버전은 3.9를 사용할 것입니다.)
11. 새로운 패키지를 설치할 것을 묻는데, 'y'입력 합니다.
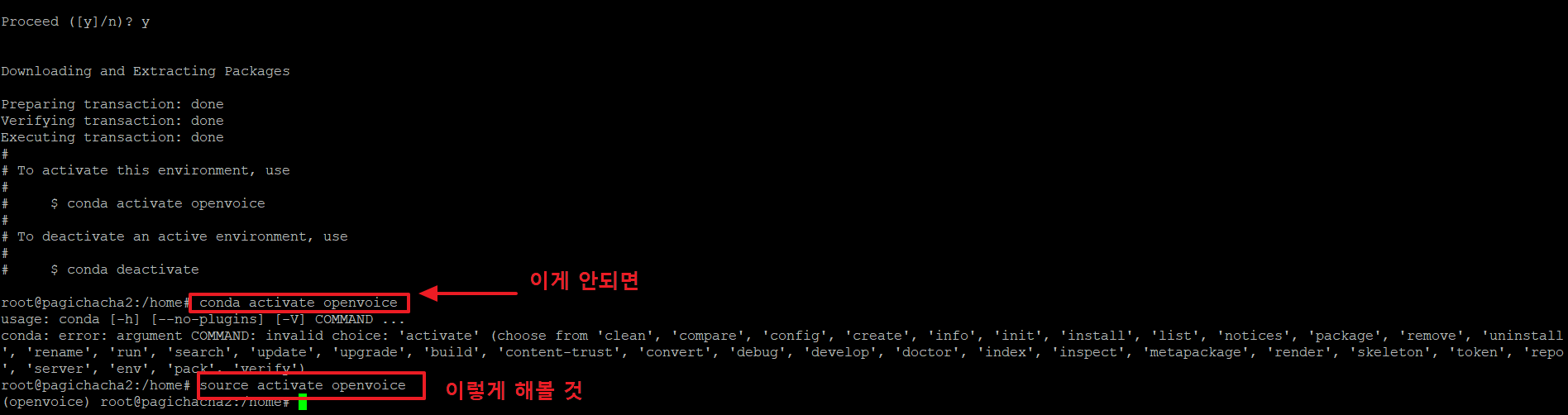
12. 가상환경으로 진입하려면 아래와 같은 명령을 사용하여 진입합니다.
>conda activate openvoice
위의 명령이 안되는 경우 아래 명령을 사용합니다.
>source activate openvoice
II. openvoice 활용하기
13. 다양한 음성을 활용하기 위해 우리는 openvoice를 사용할 예정이며, 아래 git에서 openvoice에서 제공하는 파일을 다운로드 받습니다.
>git clone https://github.com/myshell-ai/OpenVoice.git
위 명령 실행 후 무엇이 받아졌는지 ls명령으로 확인합니다.
>ls
아래 그림처럼 'OpenVoice' 디렉토리가 생성된 것을 알 수 있습니다.
>cd OpenVoice 명령으로 해당 디렉토리로 이동 후 어떤 파일들이 생성되었는지 살펴 봅니다.

14. 아래 명령으로 현재 디렉토리의 소스코드를 기반으로 파이썬 패키지를 개발 모드로 설치합니다.
15. 아래와 같이 'successfully~~' 가 보이면 잘 설치된 것입니다.
16. openvoice를 사용하기 위해 아래와 같은 명령으로 checkpoints 파일을 다운로드 받습니다.

17. 다운로드 받은 zip파일의 압축을 아래 명령으로 해제합니다.
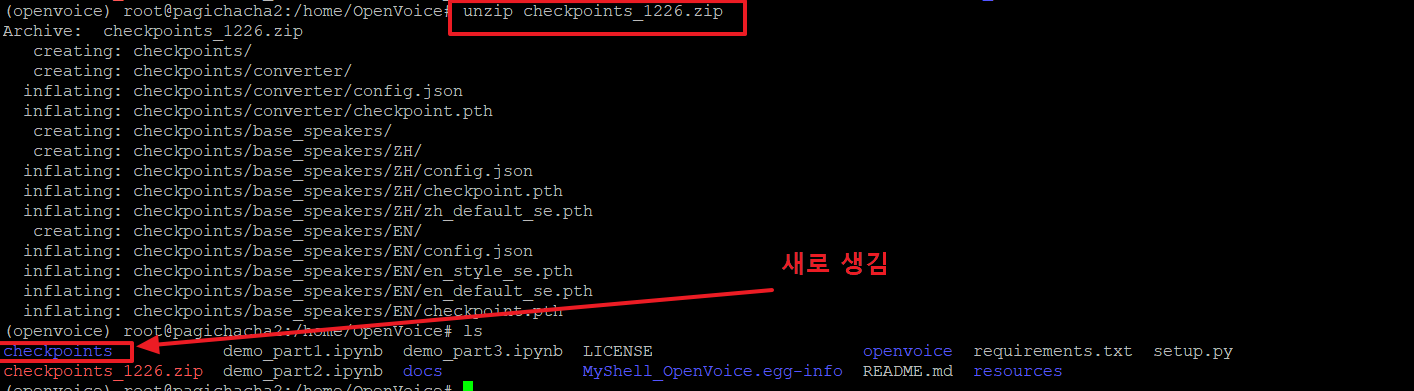
18. 파이썬 소스코드를 만들어서 한번에 실행할 예정이므로 아래와 같이 코딩 후 복사한 다음 vi 편집기를 열어서 붙여 넣습니다.
# 음성 스타일 컨트롤 데모
import os
import torch
from openvoice import se_extractor
from openvoice.api import BaseSpeakerTTS, ToneColorConverter
# Initialization
ckpt_base = 'checkpoints/base_speakers/EN'
ckpt_converter = 'checkpoints/converter'
device="cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = 'outputs'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
# 톤 색상 임베딩 획득
# source_se는 기본 스피커의 톤 색상 임베딩입니다. 기본 스피커에서 생성된 여러 문장의 평균입니다.
# 여기서 결과를 직접 제공하지만 독자는 source_se를 자유롭게 추출할 수 있습니다.
source_se = torch.load(f'{ckpt_base}/en_default_se.pth').to(device)
# 아래 reference_speaker.mp3는 음성을 복제하려는 reference의 짧은 오디오 클립을 가리킵니다.
# 여기에 예를 제공합니다. 만약 당신이 당신 자신의 참조 스피커를 사용한다면, 각 스피커가 고유한 파일 이름을 가지고 있는지 확인하십시오.
# se_extractor는 오디오의 파일 이름을 사용하여 target_se를 저장하고 자동으로 덮어쓰지 않습니다.
reference_speaker = 'resources/example_reference.mp3' # This is the voice you want to clone
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)
# Inference(추론)
save_path = f'{output_dir}/output_en_default.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='English', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
# 다양한 스타일과 속도를 사용해 보세요. 스타일은 base_speaker_tts.tts 방식의 스피커 매개 변수에 의해 제어될 수 있습니다.
# 사용 가능한 선택 사항: 친근함, 쾌활함, 흥분함, 슬퍼함, 분노, 겁에 질린, 고함, 속삭임. 톤 색상 임베딩을 업데이트해야 합니다.
# 속도는 속도 매개 변수에 의해 제어될 수 있습니다. 속도 0.9로 속삭임을 시도해 보겠습니다.
source_se = torch.load(f'{ckpt_base}/en_style_se.pth').to(device)
save_path = f'{output_dir}/output_whispering.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='whispering', language='English', speed=0.9)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
# 다양한 언어로 시도해 보세요. 오픈보이스는 기본 스피커를 교체하기만 하면 다국어 음성 복제를 달성할 수 있습니다.
# 여기에 중국어 기본 스피커를 사용한 예를 제공하며 독자들에게 자세한 데모를 위해 demo_part2.ipynb를 시도해 보도록 권장합니다.
ckpt_base = 'checkpoints/base_speakers/ZH'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
source_se = torch.load(f'{ckpt_base}/zh_default_se.pth').to(device)
save_path = f'{output_dir}/output_chinese.wav'
# Run the base speaker tts
text = "今天天气真好,我们一起出去吃饭吧。"
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='Chinese', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
# 영원히 기술입니다. OpenVoice를 공용으로 배포할 사람들을 위해: 잠재적인 오용을 방지하기 위해 워터마크를 추가할 수 있는 옵션을 제공합니다.
# ToneColorConverter 클래스를 참조하십시오. MyShell은 워터마크가 추가되는지 여부에 관계없이 OpenVoice에서 오디오가 생성되는지 여부를 감지할 수 있는
# 기능을 보유하고 있습니다.
>vi openvoice_part1.py
<-- 편집상태에서 'i'를 입력하여 입력모드에서 붙여넣기를 하시면 됩니다.(설명하기 좀 어렵네요. ㅠ ㅠ)
openvoice_part1.py 파일이 생성되었으면 아래와 같이 실행권한을 추가합니다.
>chmod 700 openvoice_part1.py
그리고 아래 명령으로 파이썬을 실행합니다.
>python3 openvoice_part1.py
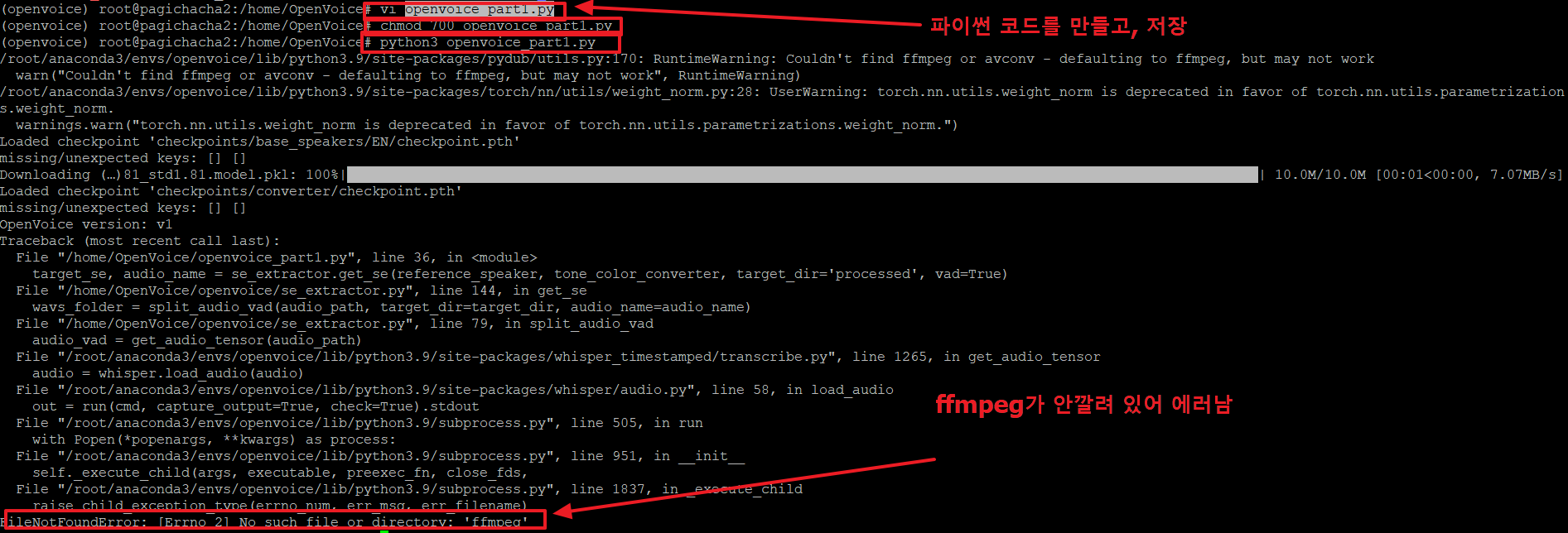
그런데 위 그림과 같이 'ffmpeg' 파일이 존재하지 않는다는 에러가 발생하였습니다.
19. ffmpeg를 설치하기 위해서 아래와 같이 진행합니다.
>sudo apt update <-- 패키지를 최신으로 업데이트 합니다.
20. 아래 명령으로 ffmpeg를 설치 합니다.
>sudo apt install ffmpeg
아래 '계속하시겠습니까?' 가 나오면 'Y'를 입력합니다.
21. 다시 아래와 같이 파이썬 파일을 실행하면 잘 실행 되는 것을 볼 수 있습니다.
>python3 openvoice_part1.py
22. 실행 후 음성변조의 결과가 outputs 디렉토리에 저장됩니다. 아래와 같이 이동 후
>cd outputs
'ls' 명령으로 어떤 음성파일들이 생성되었는지 확인합니다.
총 3개의 wav 음성파일이 생성되었습니다.

23.음성파일을 리눅스 시스템에서는 들을 수 없으므로, 아래와 같이 WINSCP라는 프로그램을 사용하여 내 PC로 가져옵니다.
아래에서는 원격 리눅스 시스템의 '/home/OpenVoice/outputs/ -> 로컬 PC의 'F:\Cloud_Backup\new_V1' 으로 wav 음성파일들을 옮겼습니다.

로컬로 옮겨진 3개 파일의 음성을 들어 봅니다.
output_en_default.wav : 기본 음성
output_whispering.wav : 기본음성의 속삭임 버전
output_chinese.wav : 기본음성의 중국어 버전
24.이번에는 일론 머스크의 목소리로 위의 3가지 버전의 목소리 파일을 만들어 보겠습니다.
이를 위해서는 일론 머스크의 목소리가 필요하며, 아래 사이트에서 일론의 연설하는 목소리를 가져오겠습니다.
https://www.youtube.com/watch?v=04R7QkiL0tU
아래 코드를 실행하면 유튜브 영상에서 음성만 추출하여 파일(ElonMusk.wav)로 추출해 줍니다.
from pytube import YouTube # pip install pytube
yt = YouTube('https://www.youtube.com/watch?v=04R7QkiL0tU')
yt.streams.filter(only_audio=True).first().download(
output_path='.', filename='ElonMusk.wav')
ElonMusk.wav: 일론머스크의 대학 강연 연설 목소리
(원본 목소리에 잡음 및 타인 목소리가 섞여 있어 최종 음성의 품질이 다소 떨어집니다.)
25. 위에서 추출한 음성파일( ElonMusk.wav )을 원격 리눅스 시스템으로 업로드 합니다.
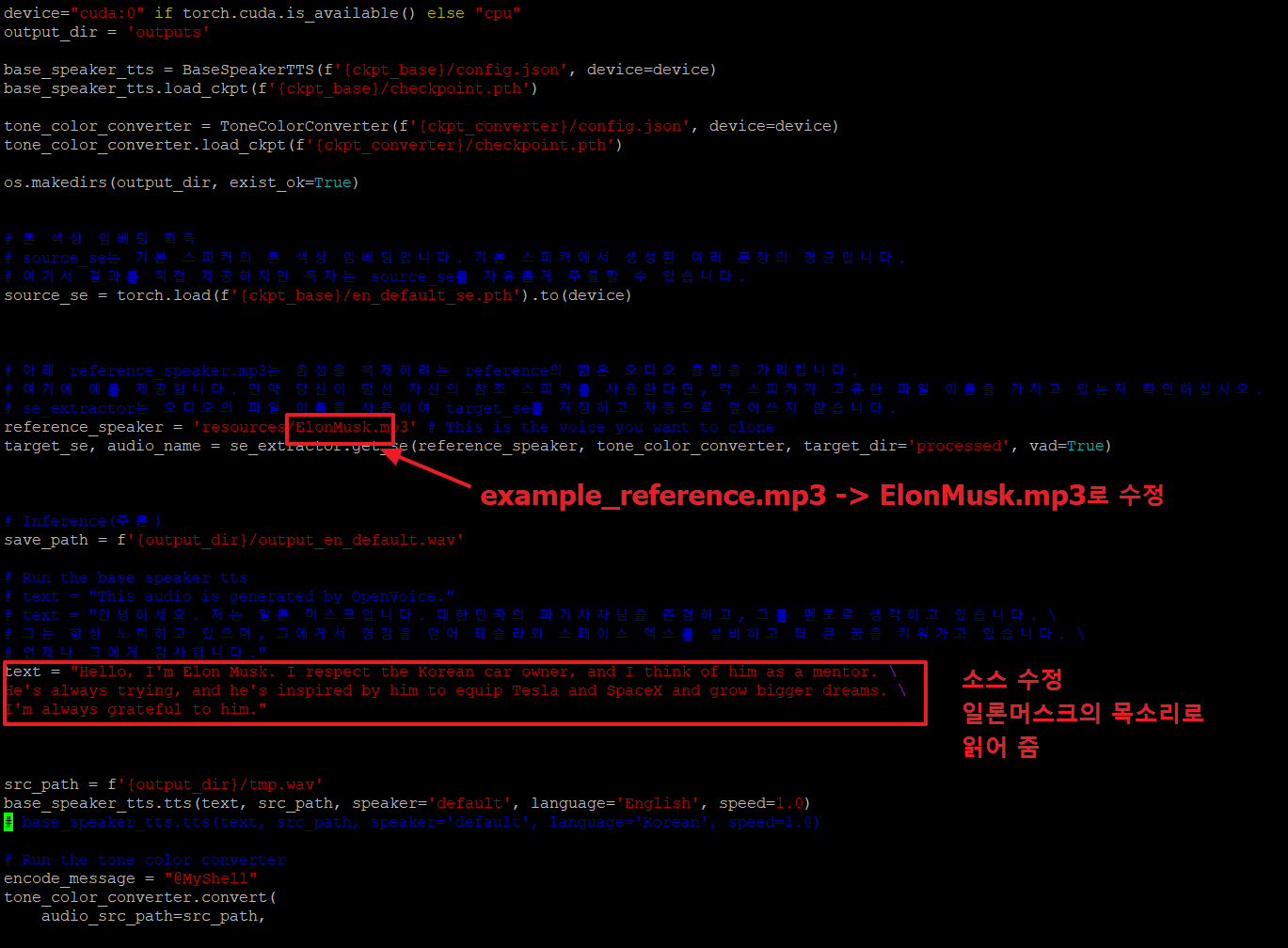
26. 아래와 같이 소스파일(openvoice_part1.py)을 vi로 열어서 수정 후
저는 아래 2곳을 수정하였습니다.
1)resources/example_reference.mp3 -> resources/ElonMusk.mp3
2)text 부분을 원하는 텍스트로 수정
다시 코드를 실행합니다.
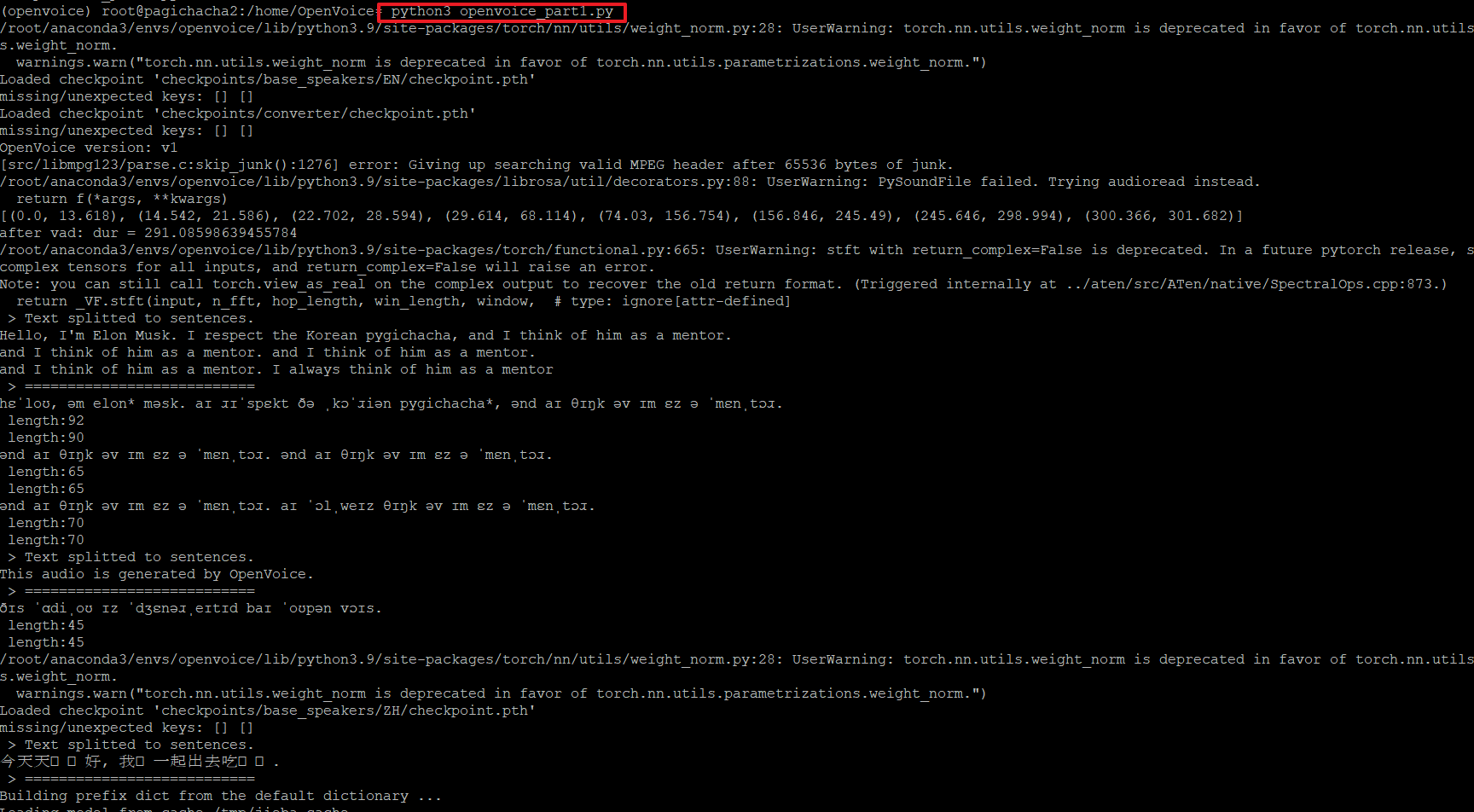
27. 위의 23번과 동일하게 로컬로 생성된 파일을 복사 후 음성파일을 들어 봅니다.

아래와 같이 일론 머스크의 목소리로 3가지 버전의 음성이 잘 생성되었음을 알 수 있습니다.
output_en_default.wav : 일론머스크의 기본음성 버전
(원본 목소리에 잡음 및 타인 목소리가 섞여 있어 최종 음성의 품질이 다소 떨어집니다. 더 좋은 품질을 원한다면 원본 파일에서 잡음제거 및 타인 목소리 제거 등 음성파일을 편집을 하셔야 합니다.)
output_whispering.wav : 일론머스크의 속삭임 버전
output_chinese.wav : 일론머스크의 중국어 버전
openvoice v1은 한국어를 지원하지 않습니다. 다음 글에서는 openvoice v2를 사용하여 일론 머스크가 한국어로 파기차차 블로그에 인사하는 등 음성을 더 다양한 방법으로 튜닝(속도, 톤 조절 등)하는 방법에 대하여 알아보겠습니다.
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
감사합니다.
'파이썬 AI 실습 > (음성변조)일론머스크의 멘토가 되다!' 카테고리의 다른 글
| 음성변조 openvoice v2- 일론머스크의 멘토가 되다.!! (5) | 2024.05.05 |
|---|