ㅁ 개요
O 프로그램 소개
- 이번 글은 이전글((실습)파이썬 네이버에서 강아지로 검색 후 강아지 이미지를 자동으로 크롤링 하는 프로그램 만들기 - 10.파일이름에 특수문자 포함 시 처리하기)에 이은 12번째 글로 이미지를 현재 폴더에 저장하면 소스와 섞여 어지러워 보이므로 깔끔하게 보이도록 별도 폴더에 자동 생성하는 방법에 대해 알아보겠습니다.
O 완성된 프로그램 실행 화면
1.이전 소스코드( 10.crawing_naver.py )를 실행하면 소스코드가 위치한 경로에 이미지가 다운로드 됩니다. 여러번 실행하는 경우 이미지가 많아지고 복잡해져서 정리하기가 어렵습니다.

이미지 20장 다운로드 된 것을 볼 수 있습니다.
코드를 수정 후 다시 실행하면 아래와 같이 현재시간 기준 폴더가 생성되고, 이곳에 이미지를 다운로드 받게 되어 깔끔하게 정리된 모습으로 볼 수 있습니다.
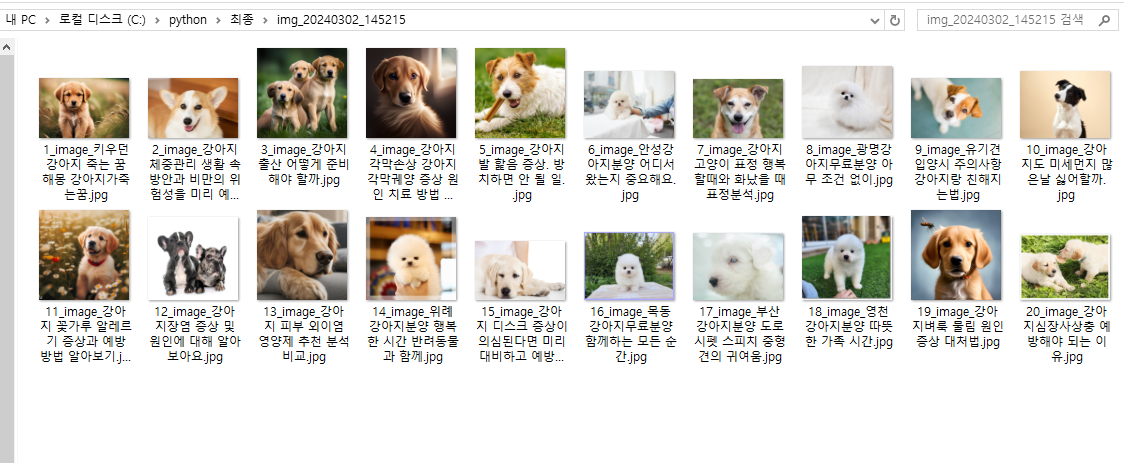
아래는 폴더 생성 이름을 img_+'현재시간(년월일_시분초)'로 만들었습니다.

ㅁ 세부 내용
O 완성된 소스
소스 : 11.crawing_naver.py
# -*- coding utf-8 -*-
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
import time
from bs4 import BeautifulSoup
import requests
import re
from datetime import datetime
import os
##########################################
# 1.셀레니움을 이용한 크롬브라우저 자동 띄우기
##########################################
s = Service("C:/download/chromedriver.exe") # Replace with the actual path
options = webdriver.ChromeOptions()
browser = webdriver.Chrome(service=s, options=options)
##########################################
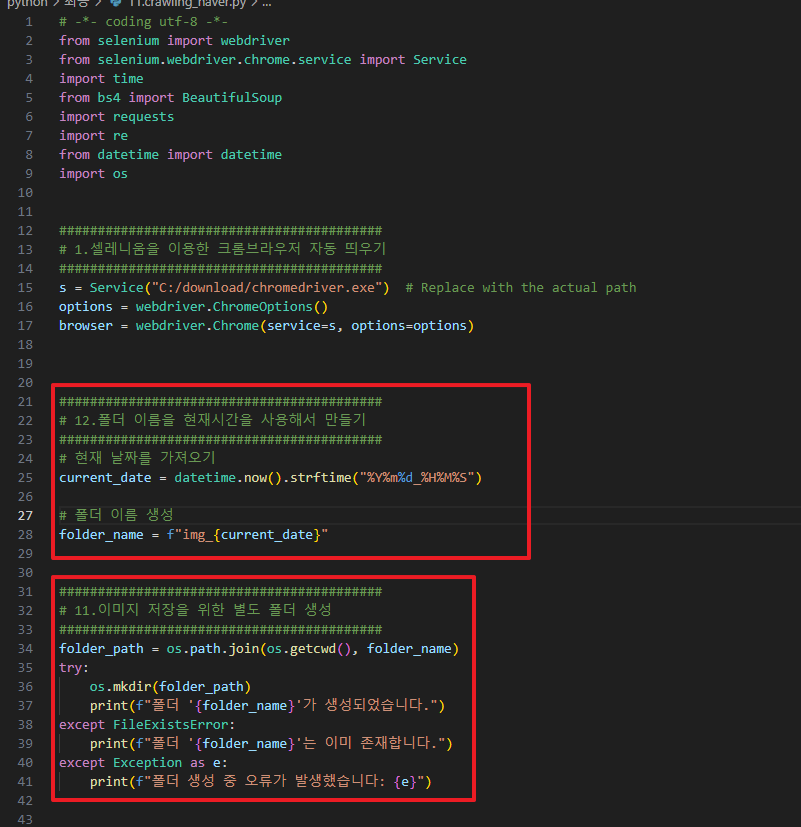
# 12.폴더 이름을 현재시간을 사용해서 만들기
##########################################
# 현재 날짜를 가져오기
current_date = datetime.now().strftime("%Y%m%d_%H%M%S")
# 폴더 이름 생성
folder_name = f"img_{current_date}"
##########################################
# 11.이미지 저장을 위한 별도 폴더 생성
##########################################
folder_path = os.path.join(os.getcwd(), folder_name)
try:
os.mkdir(folder_path)
print(f"폴더 '{folder_name}'가 생성되었습니다.")
except FileExistsError:
print(f"폴더 '{folder_name}'는 이미 존재합니다.")
except Exception as e:
print(f"폴더 생성 중 오류가 발생했습니다: {e}")
# 검색어
plusUrl = "강아지"
##########################################
# 2.네이버 검색 페이지 로딩하기
##########################################
baseUrl = 'https://search.naver.com/search.naver?where=image&sm=tab_jum&query='
url = baseUrl + plusUrl
print(url)
browser.get(url)
time.sleep(2)
##########################################
# 3.네이버 검색 페이지에서 모든 소스 가져오기
##########################################
html_source = browser.page_source
# print(html_source,"\n\n\n\n++++++++++++++++++++++++++++++++++++++++++++++")
soup = BeautifulSoup(html_source, 'html.parser')
# print(soup)
##########################################
# 4.가져온 소스 필터링 테스트 하기
##########################################
# 가져온 소스에서 이미지 태크의 클래스 속성이 '_fe_image_tab_content_thumbnail_image' 인것을 가져와 보기
img = soup.find('img', {'class': '_fe_image_tab_content_thumbnail_image'})
# print(img)
# https://search.pstatic.net/common/?src=http%3A%2F%2Fblogfiles.naver.net%2FMjAyNDAxMDhfOTEg%2FMDAxNzA0NjgzOTQwMTAx.JKnvEIv6ST9A9IW6iTtTtAR2MtkkBaRPlF_--TLfUfIg.KAh-qQql-eBqUuP2Kkb2yGj2pdSMNRVM3KosTAiTVdQg.JPEG.rkddl2001tmf%2Fth_%252817%2529.jpg&type=a340
############################################################
# 5.가져온 소스에서 이미지 링크와 설명만 뽑아서 리스트에 담아두기
############################################################
image_links = []
image_alts = []
for img in soup.find_all('img', {'class': '_fe_image_tab_content_thumbnail_image'}):
image_links.append(img['src'])
image_alts.append(img['alt'])
# print(image_links,"\n\n")
# print(image_alts)
############################################################
# 6.이미지 링크와 설명 가공하기(원하는대로 만들기)
############################################################
j = 20 # 가져올 이미지 수
result = list(zip(image_links[:j], image_alts[:j]))
# print(result,"\n")
# print(result[0],"\n")
############################################################
# 7.이미지를 다운로드하고, 이미지 파일이름 만들기
############################################################
# for i, (link, alt) in enumerate(list(zip(image_links[:j], image_alts[:j])), start=1):
for i, (link, alt) in enumerate(zip(image_links[:j], image_alts[:j]), start=1):
print(link)
# enumerate() 함수는 Python에서 반복 가능한(iterable) 객체(리스트, 튜플, 문자열 등)를 입력으로 받아
# 각 요소의 인덱스(index)와 값을 동시에 반환하는 반복자(iterator)를 생성
############################################################
# 10.인코딩된 이미지 제외하기
############################################################
if link.split(':')[0] == 'https':
img_data = requests.get(link).content
# print(img_data)
filename = f'{i}_image_{str(alt)}.jpg'
print(filename)
############################################################
# 9.파일이름에 특수문자 포함 시 처리하기
############################################################
filename = re.sub(r'[^\w\s.]', '', filename)
############################################################
# 8.PC에 다운로드한 이미지를 저장하기
############################################################
with open(filename, 'wb') as f:
f.write(img_data)
print(plusUrl, "이미지가 내PC에 잘 저장되었습니다.")
print("\n")
# 개선사항(숙제)
# 9.인코딩된 이미지를 어떻게 다운로드하여 저장할 것인지
# 10.파일로 저장시 파일이름에 특수문자가 포함된 경우의 처리를 어떻게 할 것인지
# 11.이미지 저장시 현재폴더가 아닌 별도 폴더 생성 후 해당 폴더에 어떻게 저장할 것인지
# 12.폴더 이름을 현재시간을 사용해서 만들려면 어떻게 하면 되는지
# >예: img_20240301_113242
# 13.많은 이미지를 받을 경우 페이지를 내린 후 받아야 하는데 이를 어떻게 해결할 것인가?
O 소스 실행
O 주요 내용
아래 소스에 대해 간략히 설명하면 다음과 같습니다.
line 25: 현재 날짜를 초단위로 가져와서 current_date변수에 저장합니다.(예: 20240301_144311)
line 28 : 위에서 가져온 현재 날짜와 'img_' 문자열을 합쳐서 폴더이름을 만듭니다.(folder_name변수에 할당)
line 34 : os.getcwd()함수로 경로정보를 얻고, 이 경로와 folder_name을 합쳐서 full path를 folder_path 변수에 할당합니다.
line 36 : os.mkdir()함수로 위에서 만든 해당경로의 폴더이름으로 폴더를 생성합니다.
line 37~41 : 폴더 생성시 오류가 발생하면 해당 메시지를 뿌려줍니다.
ㅁ 정리
O 우리가 배운 내용
- 오늘 우리가 배운 내용 중 가장 중요한 부분을 꼽으라면 아래와 같습니다.
아래 주석 참조
-다음 시간에는 폴더 이름이 생성시 마다 자동으로 변경될 수 있도록 현재시간을 이용하여 만드는 방법에 대해 알아봅니다.
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
감사합니다.