ㅁ 개요
O 프로그램 소개
- 이번 글은 이전글( (실습)파이썬 네이버에서 강아지로 검색 후 강아지 이미지를 자동으로 크롤링 하는 프로그램 만들기 - 2.네이버 검색 페이지 로딩하기)에 이은 4번째 글로 BeautifulSoup로 가져온 데이터 중에서 '강아지' 이미지 태그 부분만 가져오도록 필터링하는 방법에 대해 알아 보겠습니다.
O 완성된 프로그램 실행 화면
1.소스코드를 실행하면 아래와 같이 검색결과를 가져와서 보여줍니다.
첫번째 보여주는 것은 html 그대로의 소스입니다.
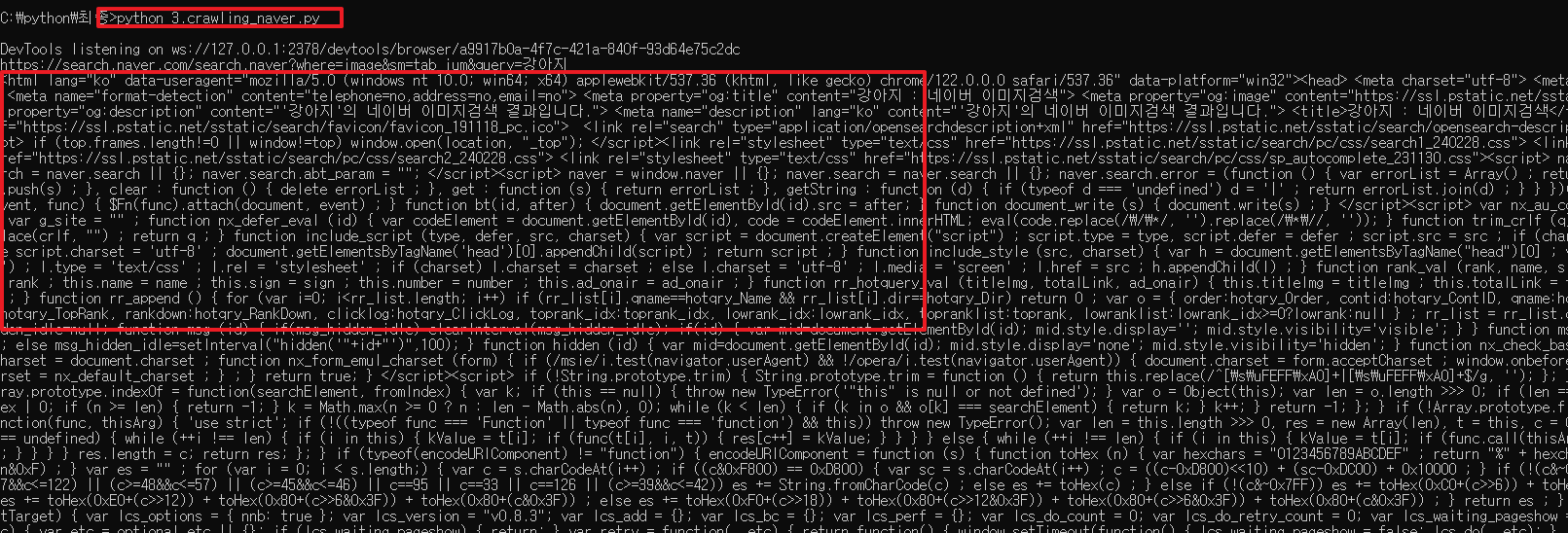
두번째 보여주는 것은 html 소스를 파싱해서 결과를 보여줍니다.

ㅁ 세부 내용
O 완성된 소스
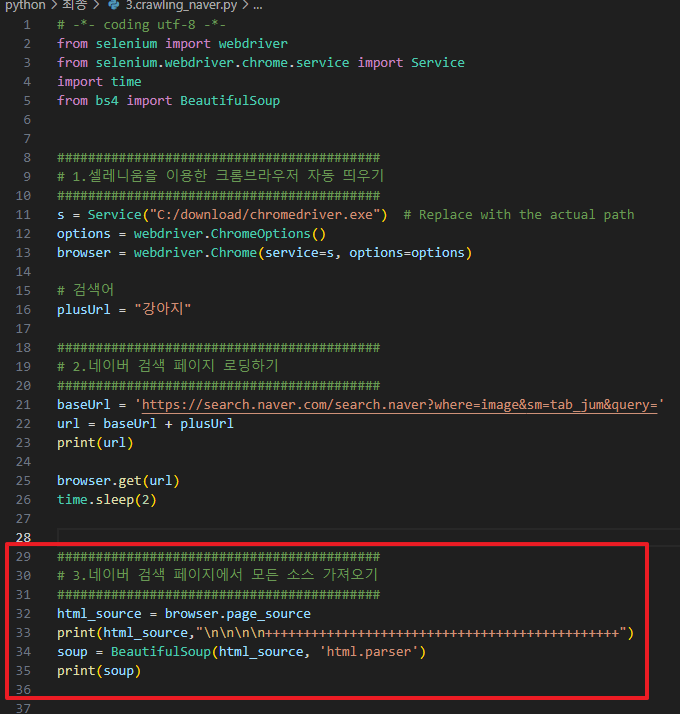
소스 : 3.crawing_naver.py
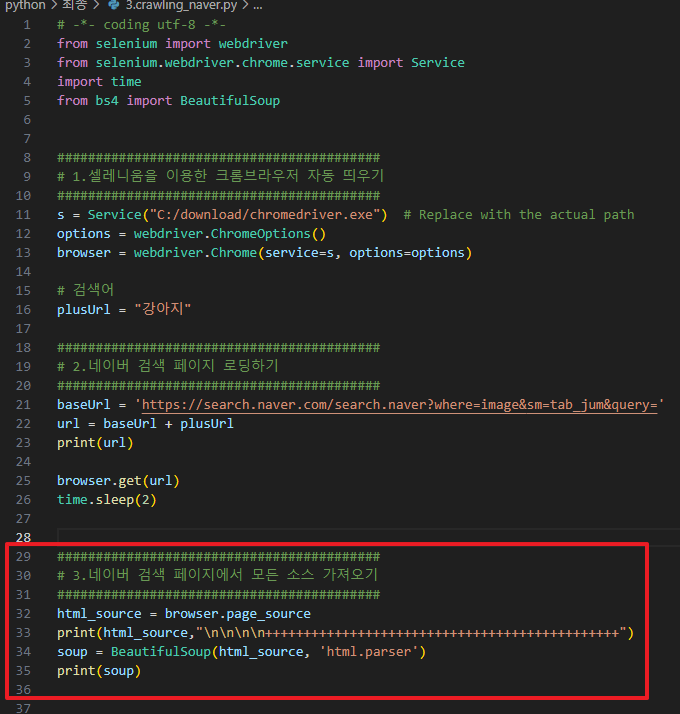
O 소스 실행
O 주요 내용
아래 소스에 대해 간략히 설명하면 다음과 같습니다.
line 32~33 : 이전 시간에 만든 browser객체로 페이지소스를 가져와서 화면에 뿌려줍니다.
line 34~35: 위의 페이지소스를 html.parser로 파싱 후 soup변수에 담아서 다시 화면에 출력합니다.
파싱하는 경우 날 html소스보다 보기 좋게된 형태로 가져옵니다.
ㅁ 정리
O 우리가 배운 내용
- 오늘 우리가 배운 내용 중 가장 중요한 부분을 꼽으라면 아래와 같습니다.
브라우저 객체로 페이지 소스를 가져오고, 이를 다시 BeautifulSoup객체의 html.parser로 파싱하여 가져옵니다.
- 다음 시간에는 이번 시간에 가져온 이미지 태크의 속성 중에서 'src' 와 'alt' 만 가져와서 리스트에 담는 방법에 대해 설명합니다
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
감사합니다.