ㅁ 개요
O 프로그램 소개
- 이번 글은 이전글(파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 3.변경 사항 체크하기파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 4.유튜브 영상 다운로드 하기)에 이은 6번째 마지막 글로 이전 글들의 내용을 종합하여 원하는 유튜버의 새로운 영상이 올라오면 텔레그램으로 새로운 영상이 올라왔다고 알려주고, 실시간으로 영상을 다운로드 받는 방법에 대하여 알아보겠습니다.
O 완성된 프로그램 실행 화면
- 최종 완성된 프로그램의 결과화면은 아래와 같습니다..
1.프로그램을 실행하면 아래와 같이 실행됩니다.
유튜브 영상이 새로 올라 왔는지 20초 마다 계속 체크합니다.

2.새로운 영상이 올라왔습니다.
먼저 텔레그램 메신저로 새로운 영상이 추가되었다는 알림이 옵니다.

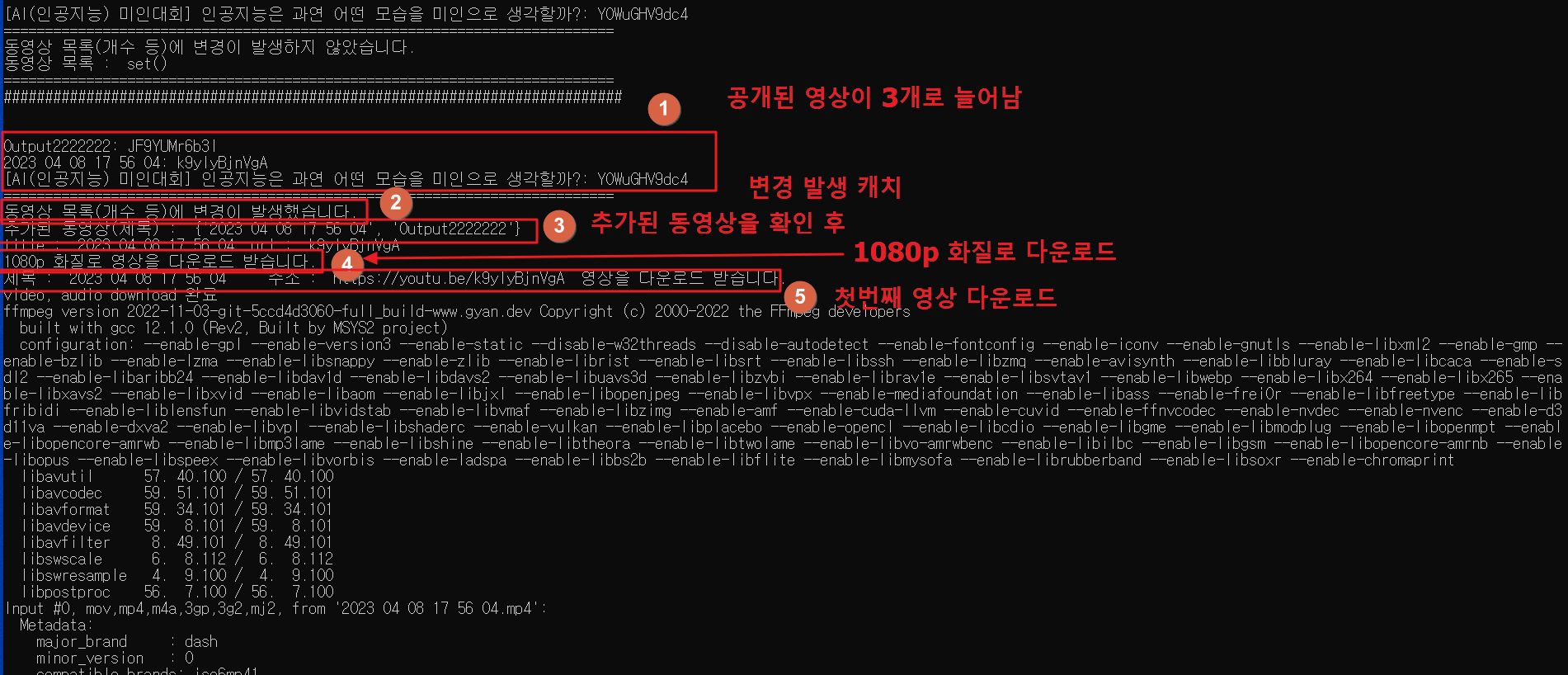
3. 새로 추가된 영상을 다운로드 합니다.
공개된 영상이 1개 -> 3개로 늘었으며, 추가된 2개 영상을 1080p 화질로 다운로드 합니다.
(1080p 화질로 다운받는 것은 대신 시간 소요가 많습니다.)
먼저 첫번째 영상을 다운로드 합니다.
4. 두번째 영상을 1080p 화질로 다운로드 합니다.
어떠한 이유로 다운로드가 실패하였습니다. 이런 경우 다시 화질을 낮추어 720p 화질로 다운로드 합니다.
이후 다운로드가 완료되었고, 변경사항이 없으므로 다시 모니터링(변경여부 체크) 모드로 돌아갑니다.

5. 윈도우 탐색기에서 확인 결과 영상이 잘 다운로드 된 것을 볼 수 있습니다.

ㅁ 세부 내용
O 완성된 소스
소스 : 9.down_runtime_C2.py
from googleapiclient.discovery import build
from googleapiclient.errors import HttpError
import time
from datetime import datetime
from pytube import YouTube
import os
import ffmpeg
import telegram
from conf import *
# 텔레그램 메신저를 사용하기위한 토큰 설정부분
bot = telegram.Bot(token=TELEGRAM_TOKEN)
# YouTube Data API의 API key를 입력합니다.
api_key = YOUTUBE_APIKEY
# 가져올 채널의 ID를 입력합니다.
channel_id = 'UChBYnUkgXUk2rmkQlIMNXNw'
# YouTube Data API 클라이언트를 빌드합니다.
youtube = build('youtube', 'v3', developerKey=api_key)
############################################################################
# 화질 720
def on_progress(vid, chunk, bytes_remaining):
total_size = vid.filesize
bytes_downloaded = total_size - bytes_remaining
percentage_of_completion = bytes_downloaded / total_size * 100
totalsz = (total_size/1024)/1024
totalsz = round(totalsz,1)
remain = (bytes_remaining / 1024) / 1024
remain = round(remain, 1)
dwnd = (bytes_downloaded / 1024) / 1024
dwnd = round(dwnd, 1)
percentage_of_completion = round(percentage_of_completion,2)
#print(f'Total Size: {totalsz} MB')
print(f'Download Progress: {percentage_of_completion}%, Total Size:{totalsz} MB, Downloaded: {dwnd} MB, Remaining:{remain} MB')
# 화질 720
def download_youtube_720(title, url):
url = 'https://youtu.be/' + url
print("제목 : ", title, "\t주소 : ", url, " 영상을 다운로드 받습니다.")
bot.sendMessage(chat_id=TELEGRAM_CHAT_ID, text="제목 : "+title+"\t주소 : "+url+" 영상을 다운로드 받습니다.")
# url = 'https://www.youtube.com/watch?v=4ASVa2HPr6M&t=9s'
YouTube(url, use_oauth=True, allow_oauth_cache=True, on_progress_callback=on_progress).streams.filter(res="720p").first().download()
if os.path.exists(title+'.mp4'):
os.rename(title+'.mp4', title+"_720p_"+date__+'.mp4')
# 화질 1080
def download_youtube_1080(title, url):
url = 'https://youtu.be/' + url
print("제목 : ", title, "\t주소 : ", url, " 영상을 다운로드 받습니다.")
bot.sendMessage(chat_id=TELEGRAM_CHAT_ID, text="제목 : "+title+"\t주소 : "+url+" 영상을 다운로드 받습니다.")
# youtube = YouTube('https://youtu.be/JF9YUMr6b3I') # 유튜브 영상 주소
youtube = YouTube(url, use_oauth=True, allow_oauth_cache=True) # 유튜브 영상 주소
video = youtube.streams.filter(res="1080p").first().download()
os.rename(video,"video_1080.mp4")
audio = youtube.streams.filter(only_audio=True)
audio[0].download()
print("video, audio download 완료")
# 비디오와 오디오를 합쳐서 최종 영상 생성
video_stream = ffmpeg.input('video_1080.mp4')
title = title.replace(".","") #<-------- 영상제목에 "." 가 포함된 경우 삭제되므로 이를 제거해 주어야 에러가 발생하지 않음
audio_stream = ffmpeg.input(title+'.mp4') # 유튜브 영상 제목
ffmpeg.output(audio_stream, video_stream, 'out.mp4').run()
if os.path.exists('video_1080.mp4'):
os.remove('video_1080.mp4')
if os.path.exists(title+'.mp4'):
os.remove(title+'.mp4')
if os.path.exists('out.mp4'):
os.rename('out.mp4', title+"_1080p_"+date__+'.mp4')
########################################################################
beforeVideos = [] # 현재 비디오 목록 10개
beforeVideos_dic = {}
try:
# 동영상 목록을 가져옵니다.
request = youtube.search().list(
part='id,snippet',
channelId=channel_id,
order='date',
type='video',
maxResults=10
)
response = request.execute()
# print(response)
# 동영상 제목과 ID를 출력합니다.
for item in response['items']:
video_title = item['snippet']['title']
video_id = item['id']['videoId']
print(f'{video_title}: {video_id}')
beforeVideos.append(video_title)
beforeVideos_dic[video_title] = video_id
beforeSet = set(beforeVideos) # 현재 비디오 목록 10개, set으로 만들어야 뺄 수 있음
# beforeSet_dic = set(beforeVideos_dic)
# print(beforeSet)
# print(beforeSet_dic)
print("==========================================================================")
except HttpError as e:
print(f'An HTTP error {e.resp.status} occurred:\n{e.content}')
time.sleep(2)
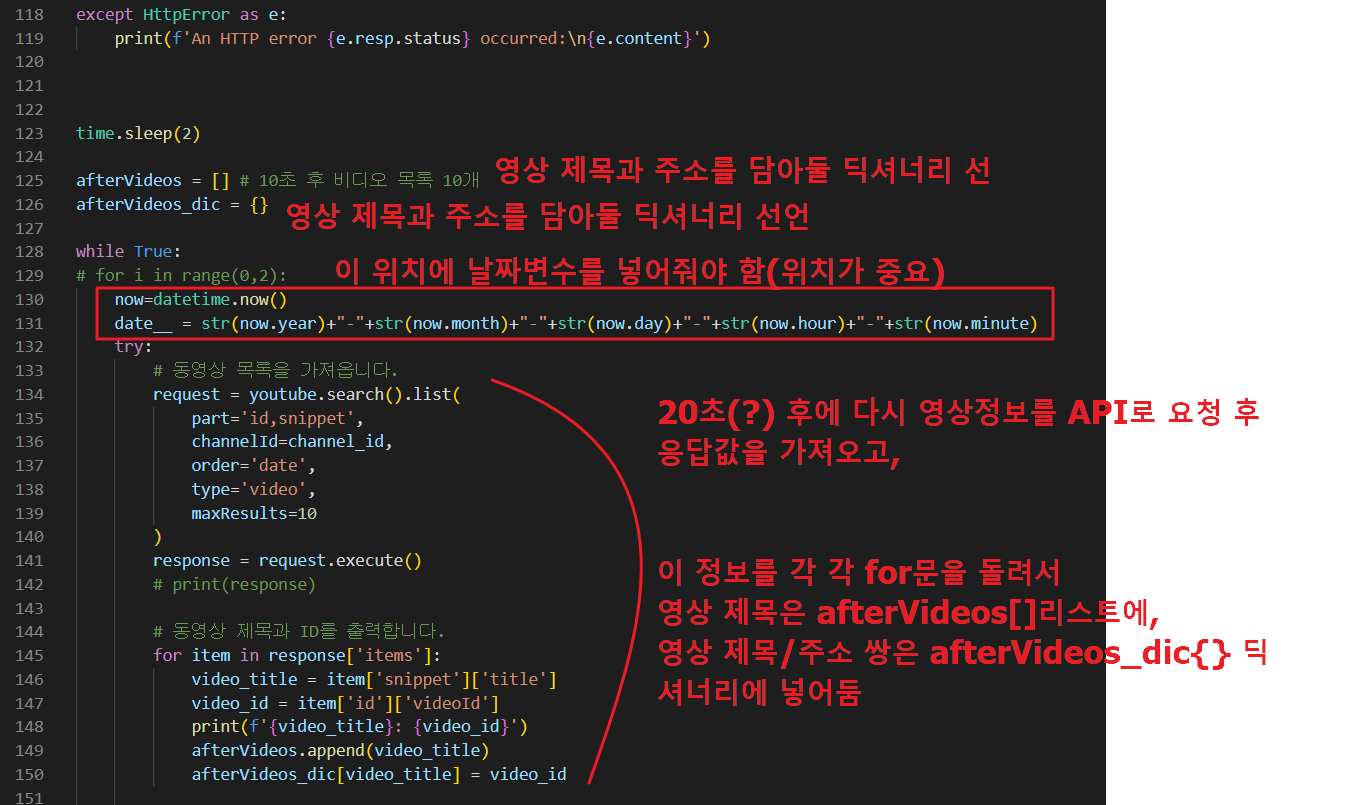
afterVideos = [] # 10초 후 비디오 목록 10개
afterVideos_dic = {}
while True:
# for i in range(0,2):
now=datetime.now()
date__ = str(now.year)+"-"+str(now.month)+"-"+str(now.day)+"-"+str(now.hour)+"-"+str(now.minute)
try:
# 동영상 목록을 가져옵니다.
request = youtube.search().list(
part='id,snippet',
channelId=channel_id,
order='date',
type='video',
maxResults=10
)
response = request.execute()
# print(response)
# 동영상 제목과 ID를 출력합니다.
for item in response['items']:
video_title = item['snippet']['title']
video_id = item['id']['videoId']
print(f'{video_title}: {video_id}')
afterVideos.append(video_title)
afterVideos_dic[video_title] = video_id
afterSet = set(afterVideos) # 10초 후 비디오 목록 10개
# afterSet_dic = set(afterVideos_dic)
# print(afterSet)
# print(afterSet_dic)
print("==========================================================================")
result = afterSet - beforeSet # afterSet이 많으면 변경발생(즉, 추가되면 변경발생), beforeSet이 많으면 변경 미발생임
# result_dic = afterSet_dic - beforeSet_dic
# print(result)
if (result):
print("동영상 목록(개수 등)에 변경이 발생했습니다.")
print("추가된 동영상(제목) : ", result)
bot.sendMessage(chat_id=TELEGRAM_CHAT_ID, text="동영상 목록(개수 등)에 변경이 발생했습니다.\n 추가된 동영상(제목) : "+str(result))
# print("추가된 동영상의 url : ", result_dic)
for item in result:
# print(item) # 추가된 동영상 제목
# 아래와 같이 다시 'afterVideos_dic.items():' <-- 이걸 쓰는 이유는 value 즉 url을 구하기 위함임, result(afterSet)만으로는 key 즉, 영상 제목만 구할 수 있으므로 별도 url을 구하는 방법이 필요했음
for key, value in afterVideos_dic.items(): # afterVideos_dic 딕셔너리 내 key(title), value(url)로 돌면서
if item == key: # 제목이 같으면(즉, 새로 추가된 영상이면 영상을 다운로드, 그렇지 않으면 다운로드하지 않음)
print("title : ",key, " url : ", value)
try:
pass
print("1080p 화질로 영상을 다운로드 받습니다.")
download_youtube_1080(key, value)
except:
pass
try:
pass
print("1080p 화질로 영상 다운로드 시 에러가 발생하여, 720p 화질로 영상을 다시 다운로드 받습니다.")
download_youtube_720(key, value)
except:
pass # 720p로 다운로드 시에도 에러 발생하면 프로그램 에러 발생으로 멈추지 않도록 pass로 통과 시킴
else:
print("동영상 목록(개수 등)에 변경이 발생하지 않았습니다.")
print("동영상 목록 : ", result)
print("==========================================================================")
print("###########################################################################\n\n")
beforeSet = afterSet
except HttpError as e:
print(f'An HTTP error {e.resp.status} occurred:\n{e.content}')
time.sleep(20) # API 요청/응답 갯수에 제한(10000/일)이 있으므로 실제로는 최소 1분~60분 정도로 늘려주어야 함
O 주요 내용
1. 소스의 주요 내용을 간략하게 살펴보겠습니다.
(대부분의 설명은 아래 주석에 달아 놓았으므로 이부분을 참고하여 주시기 바랍니다.)
관련 모듈을 임포트하고, 텔레그램, API 키, 채널ID 등을 설정해 줍니다.
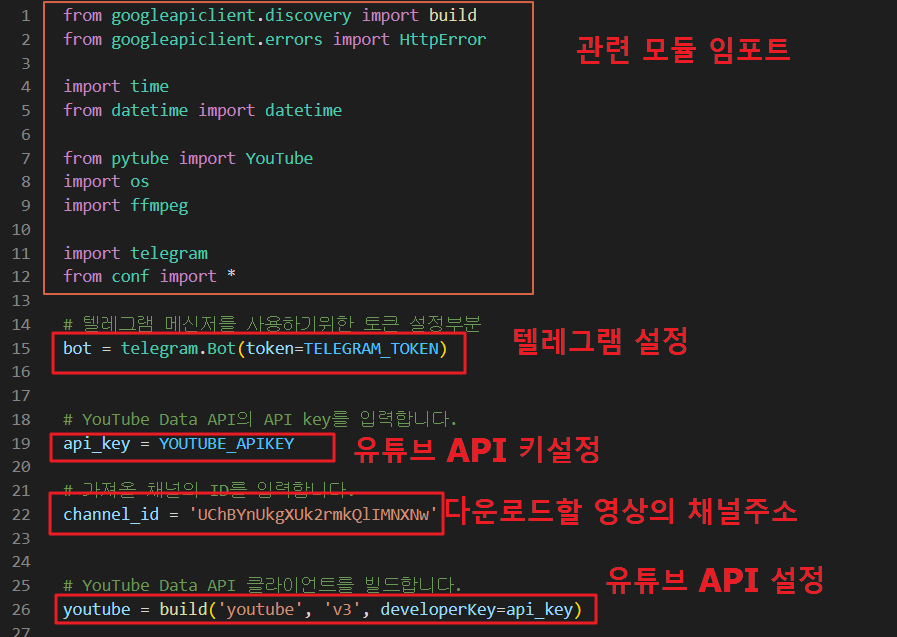
위의 채널 ID를 찾는 방법은 아래 이전 글을 참고하여 주시기 바랍니다.
https://pagichacha.tistory.com/182
720p 화질로 다운로드 하는 함수를 만들어 줍니다.
자세한 내용은 아래 이전글을 참고 하시기 바랍니다.
https://pagichacha.tistory.com/184

그리고 1080p 화질로 다운로드 하는 함수를 만들어 줍니다.
자세한 내용은 아래 이전글을 참고 하시기 바랍니다.
https://pagichacha.tistory.com/184

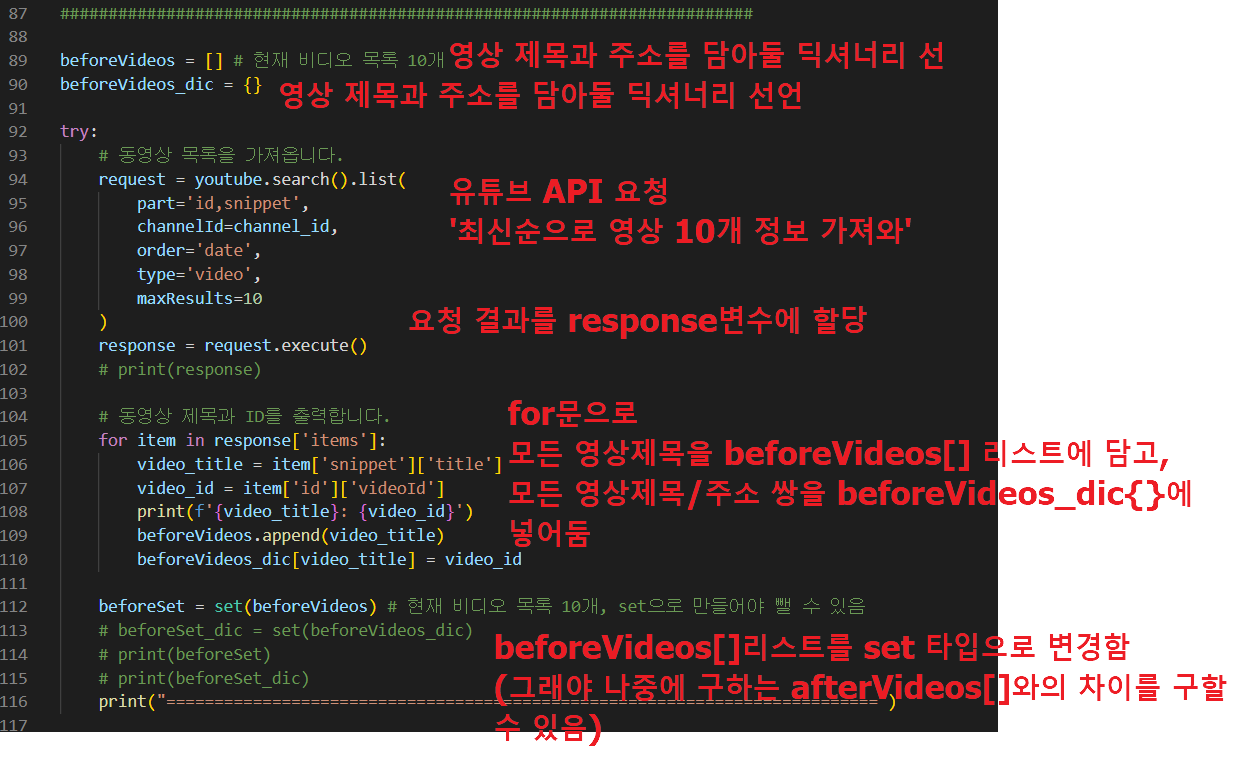
최신순으로 최근에 올라온 영상 10개에 대한 정보를 요청 후 response변수에 담습니다.(line 98~105)
가져온 정보 중에서 제목과 제목/주소로 분리하여 각 각 beforeVideos[]리스트와 beforeVideos_dic{} 딕셔너리에 담습니다.(line 109~114)
우리는 나중에 추가된 영상만 다운로드 할 것이기 때문에 '이후 영상목록'(afterVideos[])에서 '이전 영상목록'(beforeVideos[])의 차이를 구하기 위하여 beforeVideos[] 리스트를 set 타입으로 변환합니다.
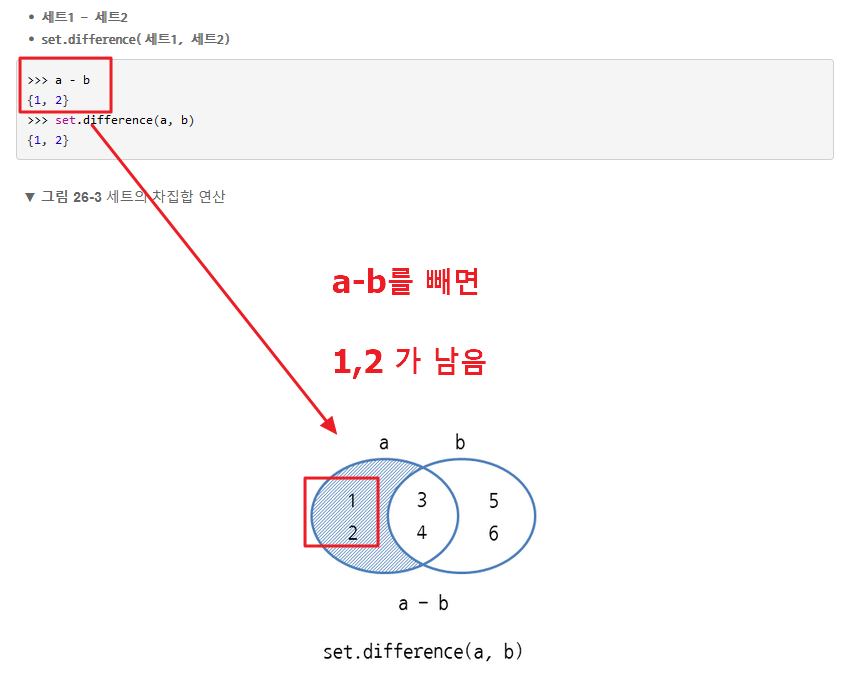
=============================================
보충 설명 : set{} 에 대한 자세한 설명은 아래를 참고해 주세요
https://velog.io/@insutance/Python-set-%EC%9D%B4%EB%9E%80
=============================================
마찬가지로 최초 2초(이후 20초) 정도 후에 아래와 같이 이후 영상목록 정보를 가져와서 동일하게 리스트와 딕셔너리에 담아 둡니다.(line 139~155)
'이후 영상목록 정보'에서 '이전 영상목록정보'의 차이를 구하고, 만일 존재하면(참이면) if문을 그렇지 않으면 else문을 실행합니다.
참인 경우 if문에서 다시 영상 주소를 가져오기 위해 이전에 담아둔 aftervideos_dic{} 딕셔너리를 for문으로 돌면서 확인합니다.
만일 새로 추가(또는 변경)된 영상 이면(if item == key:) 영상을 1080p로 다운로드 받는데,
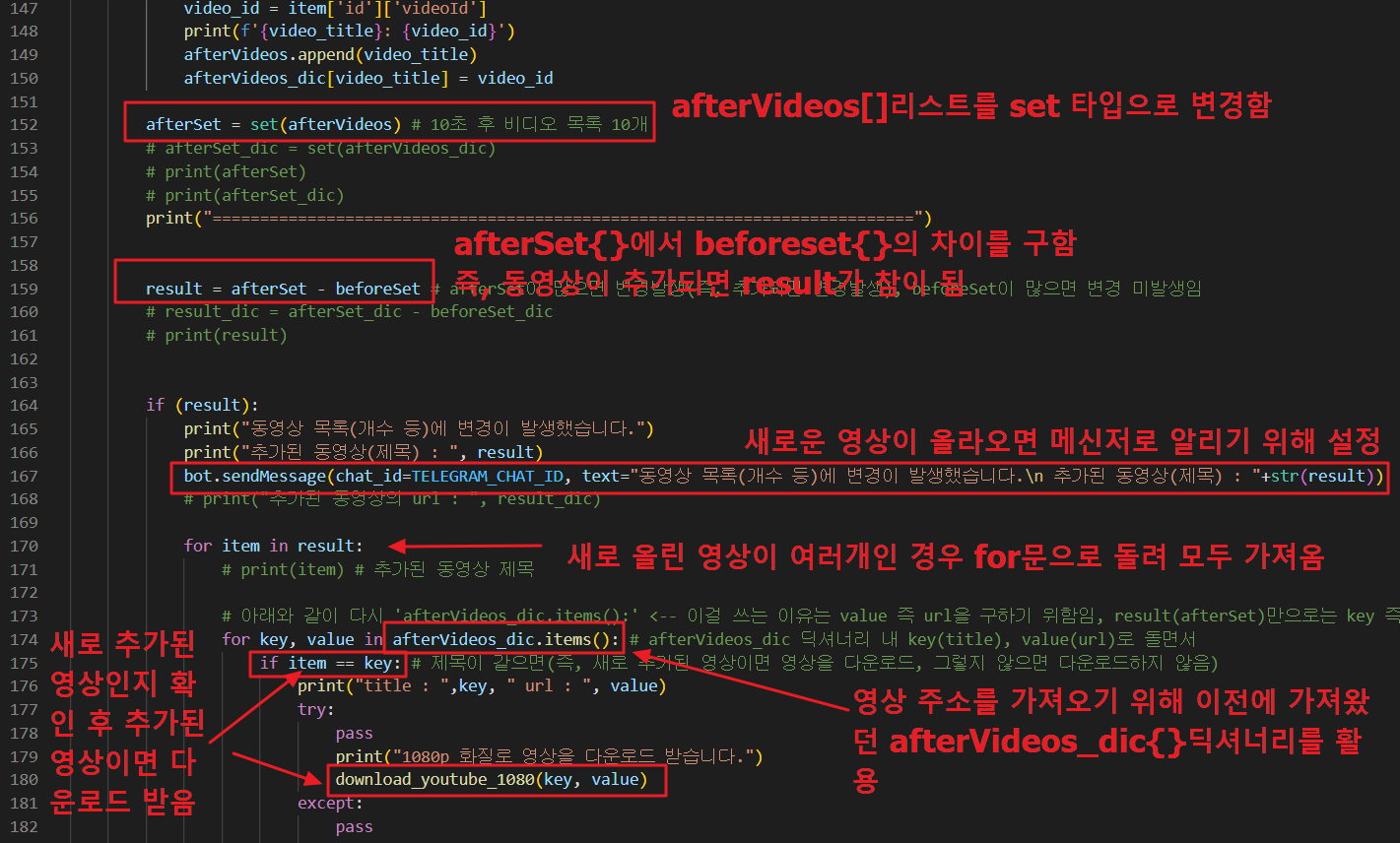
이때 에러발생 시(try~except 구문에서 except구문 실행) 다시 720p 화질로 낮춰서 영상을 다운로드 하게 됩니다.

ㅁ 정리
O 우리가 배운 내용
for key, value in afterVideos_dic.items(): # afterVideos_dic 딕셔너리 내 key(title), value(url)로 돌면서
if item == key: # 제목이 같으면(즉, 새로 추가된 영상이면 영상을 다운로드, 그렇지 않으면 다운로드하지 않음)
print("title : ",key, " url : ", value)
try: # 최초 try 구문에서는1080p 화질로 다운로드 시도
pass
print("1080p 화질로 영상을 다운로드 받습니다.")
download_youtube_1080(key, value)
except:
pass
try: # 1080p 다운로드 실패 시 화질을 낮춰 720p 로 다운로드 시도
pass
print("1080p 화질로 영상 다운로드 시 에러가 발생하여, 720p 화질로 영상을 다시 다운로드 받습니다.")
download_youtube_720(key, value)
except: # 그래도 에러가 나는 경우 새로 추가된 2번째 영상 다운로드 시도
pass
이것으로 '파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기' 편을 모두 마칩니다.
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
위의 내용이 유익하셨다면, 댓글과 하트 부탁드립니다.
감사합니다.
※ 추가적인 정보는 아래 유튜브 영상에서 해당 내용을 더욱 자세히 보실 수 있습니다.
'파이썬 실습 > 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기' 카테고리의 다른 글
| 파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 4.유튜브 영상 다운로드 하기 (0) | 2023.06.09 |
|---|---|
| 파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 3.변경 사항 체크하기 (0) | 2023.06.09 |
| 파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 2.구글 유튜브 API를 이용하여 전체영상 갯수, 제목, URL 알아내기 (0) | 2023.06.02 |
| 파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 1.구글 youtube API를 사용하기 위한 환경설정하기 (0) | 2023.06.02 |
| 파이썬 유튜브 새로운 영상 올라오면 알림 및 실시간 다운로드하기 - 0.소개편 (0) | 2023.06.02 |