ㅁ 개요
O 프로그램 소개
**본 포스팅 글은 아래 유튜브 사이트(국내 파이썬 최고 실력자 중 한 분)의 내용을 참고하여 작성하였으며, 초보자들이 좀 더 쉽고, 잘 따라할 수 있도록 해당 내용을 세부적으로 잘게 쪼개서 설명한 글입니다. 자세한 내용은 아래 사이트를 참고하여 주시기 바랍니다.
[GPT-4] 책 요약해서 유튜브 쇼츠 영상으로 돈버는 인공지능 만들기|빵형의 개발도상국
https://www.youtube.com/watch?v=_TVyF_4JJgk&t=814shttps://www.youtube.com/watch?v=sLgYJIpqUJg
O 완성된 프로그램 실행 화면
1.5페이지 분량의 책을 1페이지 단위로 끊어서 for루프로 API 요청을 하면 아래와 같이 총 2개의 요약페이지가 나옵니다.

------------------------- 여기서 프로그램의 실행결과는 끝입니다. 아래는 참고로 보시면 됩니다.
2. openai에서 API요청시 토큰의 개념을 사용하는데, 그 제한 수가 넘어가면 에러가 발생합니다.(chatGPT3.5 4097, chatGPT4.0 8096)
책의 첫페이지를 긁어서 복사 후

3.openai의 토큰라이저에 붙여 보면 그들이 얘기하는 토큰 수를 확인할 수 있습니다.
아래에서 보듯이 약 713 토큰으로 나오는데 chatGPT3.5의 경우 한번에 API요청을 4097 토큰까지 할 수 있으므로 5페이지 정도(5 X 700 = 3500 토큰) 까지는 요청이 가능합니다.
https://platform.openai.com/tokenizer

ㅁ 세부 내용
O 완성된 소스
소스 : 2.py
import re
from tqdm import tqdm
import openai
import fitz # pip install --upgrade pymupdf or pip install PyMuPDF
import time
def summary():
global summary_list
openai.api_key = 'sk-본인의 openai API키를 입력해주세요'
############### pdf to text #############################
book_path = 'paper_list/001.pdf'
doc = fitz.open(book_path)
#########################################################
start_pno = 0
summarize_every = 1
summary_list = [{
'role': 'system',
'content': 'You are a helpful assistant for summarizing books.'
}]
count = 0
content = ''
for pno in tqdm(range(start_pno, doc.page_count)):
text = doc.get_page_text(pno=pno)
# Preprocess text
text = re.sub(r"\s+", " ", text)
text = text.replace('THIRD CONCEPT, NOVEMBER 2020', '').strip()
text = ' '.join(text.split(' ')[1:])
if count == summarize_every:
messages = [{
'role': 'system',
'content': 'You are a helpful assistant for summarizing books.'
}, {
'role': 'user',
'content': f'Summarize this: {content}'
}]
# chatGPT3.5 사용시
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(res,"++++++++++++++++++++++++++++ 6")
msg = res['choices'][0]['message']['content']
print(msg,"++++++++++++++++++++++++++++ 7")
summary_list.append({
'role': 'user',
'content': msg
})
count = 0
content = ''
else:
content += text + ' '
count += 1
time.sleep(3)
return summary_list
summary()
O 주요 내용
1.아래 소스코드의 주요 부분에 대해 간략히 설명 드리겠습니다.
토큰 수 제약을 회피하기 위해서 summarize_every = 1(line 20)로 설정합니다.(사실 summarize_every = 4로 설정해도 총 5페이지니까 700 X 5 = 3500 토큰이므로 제약에 걸리지 않으나, 테스트로 1로 설정하였습니다.)
summary_list에 chatGPT의 역할과 내용을 알려줍니다. (line 21~24)
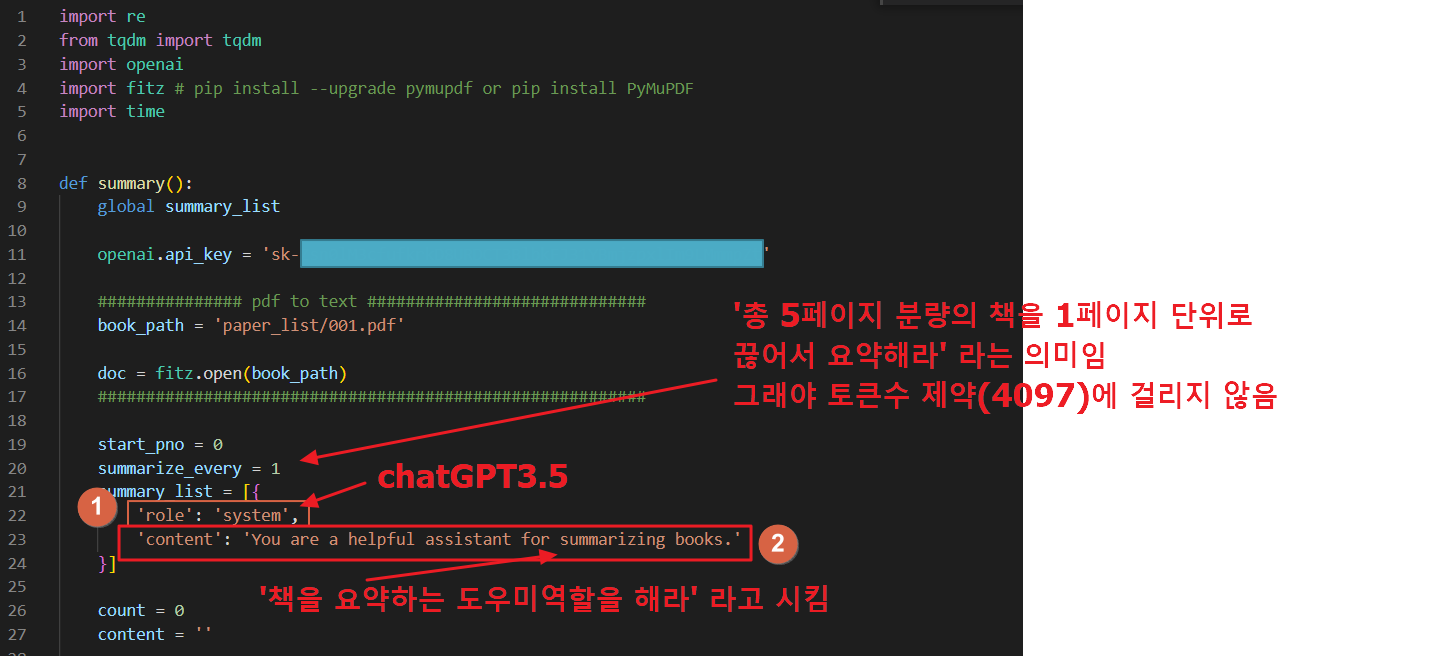
2. tqdm()(line 29)을 사용하여 for루프의 진행상황을 그래픽컬하게 표시해 줍니다.
만약 count == summarize_every 이면 즉, 토큰의 합계가 일정 수에 도달하면 chatGPT에게 API요청을 하게 하고(line 36), 그렇지 않으면 토큰이 제한 개수를 넘지 않을때 까지 페이지를 더해 줍니다.(content += text + ' ') (line 60~62)
if 구문에서는 chatGPT에게 API 요청을 해야 하므로, 역할극에서 chatGPT(system)는 책을 요약하는 도우미로, 그리고 유저(user)는 위에서 모아둔 페이지를 요약해 달라고 요청합니다. (line 37~43)
그리고나서 실제로 요약을 API로 요청하고, 응답을 받아 res변수에 담습니다.(line 45~48)
실제 필요한 부분은 책 요약 부분이므로 res에서 해당하는 부분만 필터하여 msg변수에 담습니다.(line 51)
이후 나중에 활용하기 위해서 summary_list 리스트에 위에서 요약한 내용을 append 해 둡니니다.

위의 방법은 한가지 단점이 존재하는데, 이렇게 하면 총 5페이지 분량의 책임에도 불구하고 실제 요약하는 페이지는 1,3페이지, 즉 2개 페이지만 요약하므로 요약이 제대로 되지 않을 수도 있습니다. 다만, 페이지 수가 많은 책은 별도 영향 받지 않고 요약을 잘 해줍니다.(실제 5페이지 분량의 책도 잘 요약해 주었습니다.)
총 페이지 수 : 1 2 3 4 5
if구문 실행(API요청) : 0 1 2 3 4
실제 요약 페이지 수 : XOXOX <------------ 'O' 이 2번 있으므로 요약(즉, chatGPT에게 API 요청/응답)이 2번 발생함
=>위에서 if구문 실행은 count == 1일때 즉, 1, 3에서 발생하지만, 책요약은 그 전 페이지를 요약하는 것이므로 실제는 1페이지와 3페이지가 요약됨(책의 총 페이지 수가 6페이지 였다면, 1,3, 5페이지 총 3번을 요약하게 됨)
ㅁ 정리
O 우리가 배운 내용
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
print(res,"++++++++++++++++++++++++++++ 6")
count = 0
content = ''
else: #<-- 그렇지 않으면 페이지(text)를 계속 쌓아 둔다(content += text + ' ')
content += text + ' '
count += 1
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
위의 내용이 유익하셨다면, 댓글과 하트 부탁드립니다.
감사합니다.
※ 추가적인 정보는 아래 유튜브 영상에서 해당 내용을 더욱 자세히 보실 수 있습니다.