ㅁ 개요
O 프로그램 소개
- 이번 글은 이전글([업그레이드]chatGPT API 사용 하기 - 3.chatGPT API 사용하기)에 이은 4번째 글로 chatGPT로 설명을 요청하고, 이 요청을 스테이블디퓨젼으로 이미지를 만드는 방법에 대하여 알아보겠습니다.
**본 포스팅 글은 아래 유튜브 사이트(국내 파이썬 최고 실력자 중 한 분)의 내용을 참고하여 작성하였으며, 초보자들이 좀 더 쉽고, 잘 따라할 수 있도록 해당 내용을 세부적으로 설명한 글입니다. 자세한 내용은 아래 사이트를 참고하여 주시기 바랍니다.
[출처] 자신의 상상을 그림으로 그리는 인공지능 - ChatGPT API 사용법|빵형의 개발도상국
https://www.youtube.com/watch?v=sLgYJIpqUJg
O 주요 내용
1.이미지 생성시 사용할 스테이블디퓨젼에 필요한 관련 모듈을 설치해 줍니다.
!pip install --upgrade diffusers[torch]
!pip install transformers
!pip install --upgrade accelerate

2. 아래와 같이 코딩 후 실행하면 머신러닝을 돌리기 위한 모델을 다운로드 합니다.
주의할 점은 모델을 돌릴때 GPU를 사용하므로 시작전 '런타임 환경'을 'GPU'로 바꿔 주셔야합니다.(앞글 참조)
from diffusers import StableDiffusionPipeline
import torch
model_id = 'dreamlike-art/dreamlike-photoreal-2.0'
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to('cuda')

3. prompt에 자세한 키워드로 설명하고 이를 그려달라고 요청하면, 멋지게 그려 줍니다.
prompt = 'photo, a church in the middle of a field of crops, bright cinematic lighting, gopro, fisheye lens'
pipe(prompt).images[0]
아래와 같이 시스템(chatGPT)의 역할을 정의해 줍니다.
messages = [{
'role': 'system',
'content': 'You are a helpful assistant for organizing prompt for generating images.'
}]
messages
4. 이번에는 chatGPT를 이용하여 (1)기본 요청 후 (2)세부적으로 추가 요청 후 (3)영어로 번역하고 (4)키워드로 만든 다음 이를 (5)스테이블디퓨젼으로 이미지로 만들어 보겠습니다.
이렇게 하지 않고 그냥 키워드로 만들고 이미지 생성을 해도 됩니다만, 이렇게 하는 이유는 요청이 세부적일 수록 더 디테일이 완성된 컨텐츠를 얻을 수 있기 때문입니다.
(1)기본요청 : '이 세상에서 가장 아름다운 여성의 모습을 그려줘' : 아래 그림 하단에 자세한 설명으로 응답을 주고 있습니다.
messages.append({
'role': 'user',
'content': '이 세상에서 가장 아름다운 여성의 모습을 그려줘'
})
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
msg = res['choices'][0]['message']['content']
msg

(2)세부적으로 추가 요청 : '이 여성의 외형을 더 자세하게 묘사해줘.' : chatGPT가 상상하는 여성의 모습을 더 구체적으로 설명하고 있습니다.
messages.append({
'role': 'assistant',
'content': msg
})
messages.append({
'role': 'user',
'content': '이 여성의 외형을 더 자세하게 묘사해줘.'
})
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
msg = res['choices'][0]['message']['content']
msg

(3)영어로 번역 : '위 문장을 영어로 번역해줘' : 위의 문장을 영어로 잘 번역한 것을 볼 수 있습니다.
messages.append({
'role': 'assistant',
'content': msg
})
messages.append({
'role': 'user',
'content': '위 문장을 영어로 번역해줘.'
})
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
msg = res['choices'][0]['message']['content']
msg

(4)키워드로 만든 다음 : '다음으로 구분된 명사와 형용사에 초점을 맞추도록 설명을 압축합니다' : 문장을 키워드로 만들어 줍니다.
messages.append({
'role': 'assistant',
'content': msg
})
messages.append({
'role': 'user',
'content': 'Condense the description to focus on nouns and adjectives separated by ,'
})
res = openai.ChatCompletion.create(
model='gpt-3.5-turbo',
messages=messages
)
prompt = res['choices'][0]['message']['content']
prompt

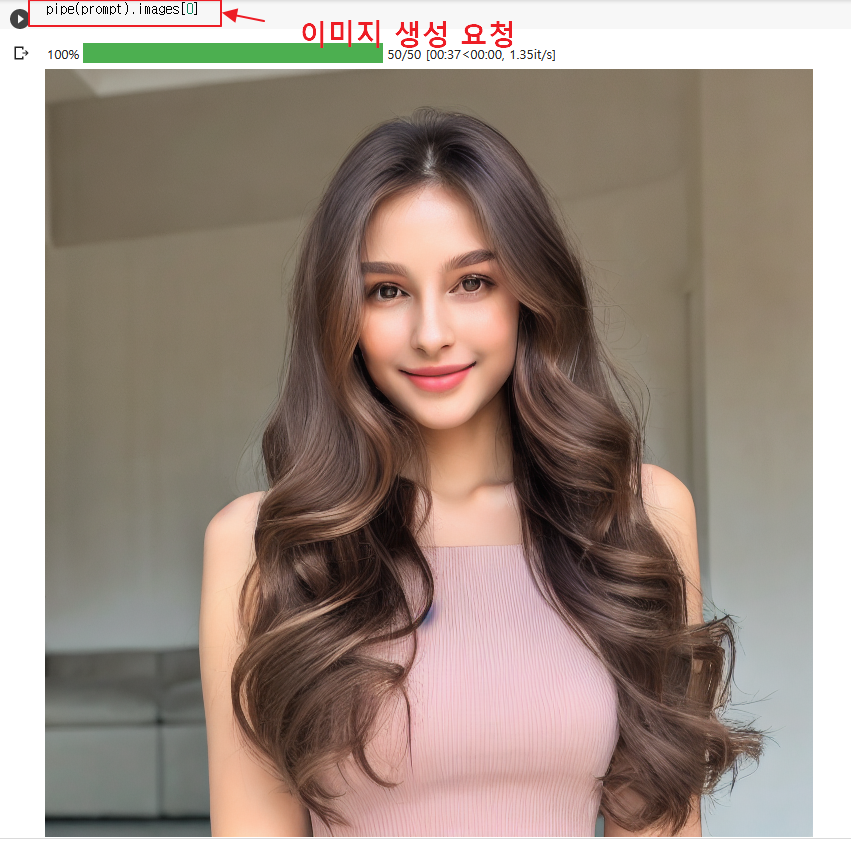
(5)스테이블디퓨젼으로 이미지로 만들어 : 스테이블디퓨젼으로 이미지 생성요청에 이미지를 잘 만든것을 볼 수 있습니다.
ㅁ 정리
O 우리가 배운 내용
- 오늘은 chatGPT로 설명을 요청하고, 이 요청을 스테이블디퓨젼으로 이미지를 만드는 방법에 대하여 알아보았습니다.
- 오늘 우리가 배운 내용을 간략히 정리해 보면 아래와 같습니다.
> 1.이미지 생성 요청 형식
from diffusers import StableDiffusionPipeline
import torch
model_id = 'dreamlike-art/dreamlike-photoreal-2.0'
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to('cuda')
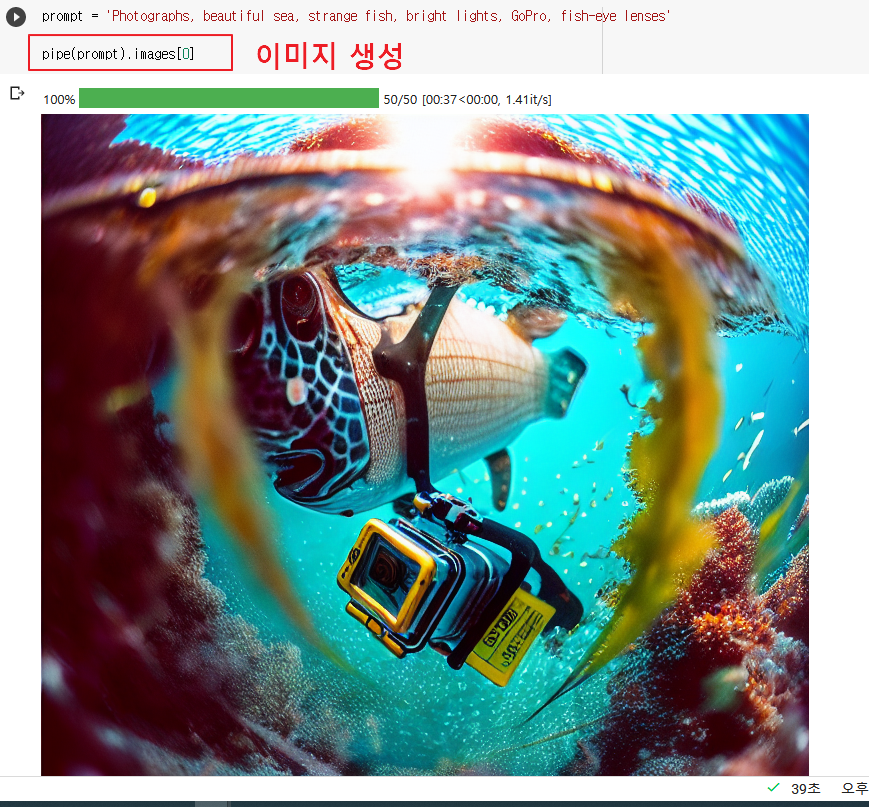
prompt = 'Photographs, beautiful sea, strange fish, bright lights, GoPro, fish-eye lenses'
pipe(prompt).images[0]
오늘은 여기까지이며, 댓글과 하트는 제가 이글을 지속할 수 있게 해주는 힘이 됩니다.
위의 내용이 유익하셨다면, 댓글과 하트 부탁드립니다.
감사합니다.
※ 추가적인 정보는 아래 유튜브 영상에서 해당 내용을 더욱 자세히 보실 수 있습니다.